What do you mean I have to redesign my entire storage platform just so a user can install an application!?!
What do you mean my legacy array/vendor is not well suited for VDI!
“Am I going to have to do a forklift upgrade to every time I want to add xxx number of users?”
“Do I really want to have one mammoth VSP/VMAX serving that many thousand desktops and acting as a failure domain for that many users?”
I’m sure other VDI Architects and SE’s in the field have had these conversations, and its always an awkward one that needs some quick white boarding to clear up. Often times this conversation is after someone has promised users that this is a simple change of a drop down menu, or after it has been implemented and is filling up storage and bringing the array to its knees. At this point the budget is all gone and the familiar smell of shame and disappointment is filling the data center as you are asked to pull off a herculean task of making a broken system work to fulfill promises that never should have been made. To make this worse broken procurement process’s often severely limit getting the right design or gear to make this work.
We’ve worked around this in the past by using software (Atlantis) or design changes (Pod design using smaller arrays) but Ultimately we have been trying to cram a round peg (Modular design storage and non-persistent desktops) into a square hole (Scale out bursting random writes, and users expecting zero loss of functionality). We’ve rationalized these decisions, (Non-Persistent changes how we manage desktops for the better!) but ultimately if VDI is going to grow out of being a niche technology it needs and architecture that supports the existing use cases as well as the new ones. Other challenges include environments trying to cut corners or deploy systems that will not scale because a small pilot worked. (try to use the same SAN for VDI and servers until scale causes problems). Often times the storage administrators or an organization is strongly bound to a legacy or unnecessarily expensive vendor or platform (Do I really need 8 protocols, and 7 x 9’s of reliability for my VDI farm?)
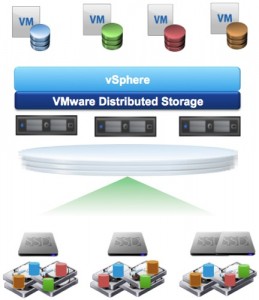
The VSAN solves not only the technical challenges of persistent desktops (Capacity/performance scale out) but also solves the largest political challenge, the entrenched storage vendor.
I’ve seen many a VDI project’s cost rationalization break down because the storage admin forced it to use the existing legacy platform. This causes one of two critical problems.
1. The cost per IOPS/GB gets ugly, or requires seemingly random and unpredictable forklift upgrades with uneven scaling of cost.
2. The storage admin underestimates the performance needs and tries to shove it all on non-accelerated SATA drives.
vSAN allows the VDI team to do a couple things to solve these problems.
1. Cost Control. Storage is scaled at the same time as the hosts and desktops in a even/linear fashion. No surprise upgrades when you run out of ports/cache/storage processor power. Adjustments in IOPS to capacity can be made slowly as nodes are added, and changing basic factors like the size of drives does not require swing migrations or rip and replace of drives.
2. Agility. Storage can be purchased without going through the storage team, and the usual procurement tar pit that involves large scale array purchases. Servers can often be purchased with a simple PO from the standard vendor. Storage expansion beyond the current vendor generally requires a barking carnival of vendor pitches, and Apples to spaceship mismatched quotes and pitches In the bureaucratic government and fortune 1000 this can turn into a year long mess that ends up under delivering. Because of the object system with dynamic protection systems non-persistent disks can be deployed with RAID 0, on the same spindles
3. Risk Mitigation. A project can start with as small as three hosts. There is not an “all in” and huge commitment of resources to get the initial pilot and sizing done, and scaling is guaranteed by virtue of the scale out design.






