vSAN Deduplication and Compression Tips!
I’ve been getting some questions lately and here are a few quick thoughts on getting the most out of this feature.
If you do not see deduplication or compression at all:
- See if the object space reservation policy has been set to above zero, as this reservation will effectively disable the benefits of deduplication for the virtual machine.
- Do not forget that swap is by default set to 100% but can be changed.
- If a legacy client or provisioning command is used that specifies “thick” or “Eager Zero Thick” this will override the OSR 100%. To fix this, you can reapply the policy. William Lam has a great blog post with some scripts on how to identify and resolve this.
- Make sure data is being written to the capacity tier. If you just provisioned 3-4 VM’s they may still be in the write buffer. We do not waste CPU or latency deduplicating or compressing data that may not have a long lifespan. If you only provisioned 10 VM’s that are 8GB each it’s quite possible that they have not destaged yet. If you are doing testing clone a lot of VM’s (I tend to create 200 or more) so you can force the destage to happen.
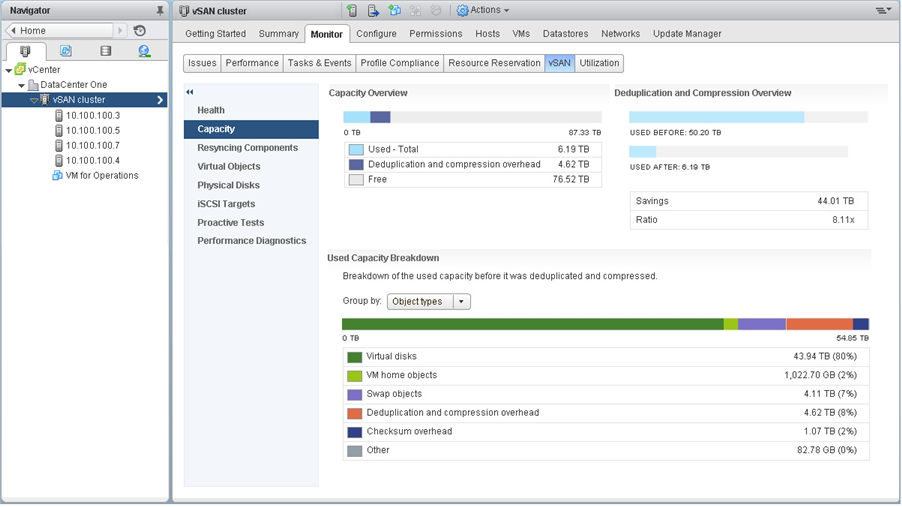
Performance anomalies (and why!) when testing vSAN’s deduplication and compression.
I’ve always felt that it’s incredibly hard to performance test deduplication and compression features, as real-world data has a mix of compressibility, and duplicate blocks and some notes I’ve seen from testing. Note: these anomalies often happen on other storage systems with these features and highlight the difficulty in testing these features.
- Testing 100% duplicate data tends to make reads and writes better than a baseline of the feature off as you avoid any bottleneck on the destage from cache process, and the tiny amount of data will end up in a DRAM cache.
- Testing data that compresses poorly on vSAN will show the little impact to read performance as vSAN will write the data fully hydrated to avoid any CPU or latency overhead in decompression (not that LZ4 isn’t a fast algorithm, to begin with).
- Write throughput and IOPS for bursts that do not start to fill up the cache show little overhead. This is true, as the data is written non-compacted to reduce latency
These quirks stick out in synthetic testing, and why I recommend reading the space efficiencies guide for guidance on using this and other features.

