I was going to update a lab host I have at home that is currently not managed by an external vCenter server. Historically I would do something like this to accomplish this task.
esxcli system settings advanced set -o /VisorFS/VisorFSPristineTardisk -i 0 cp /usr/lib/vmware/esxcli-software /usr/lib/vmware/esxcli-software.bak sed -i 's/mem=300/mem=500/g' /usr/lib/vmware/esxcli-software.bak mv /usr/lib/vmware/esxcli-software.bak /usr/lib/vmware/esxcli-software -f esxcli system settings advanced set -o /VisorFS/VisorFSPristineTardisk -i 1
You’ll also need to open and close the firewall.
esxcli network firewall ruleset set -e true -r httpClient
SO let’s put all of that into a single copy paste block?
esxcli system settings advanced set -o /VisorFS/VisorFSPristineTardisk -i 0 cp /usr/lib/vmware/esxcli-software /usr/lib/vmware/esxcli-software.bak sed -i 's/mem=300/mem=500/g' /usr/lib/vmware/esxcli-software.bak mv /usr/lib/vmware/esxcli-software.bak /usr/lib/vmware/esxcli-software -f esxcli system settings advanced set -o /VisorFS/VisorFSPristineTardisk -i 1 esxcli network firewall ruleset set -e true -r httpClient esxcli software profile update -p ESXi-8.0U3b-24280767-standard -d https://dl.broadcom.com/TOKEN_GOES_HERE/PROD/COMP/ESX_HOST/main/vmw-depot-index.xml --no-hardware-warning esxcli network firewall ruleset set -e false -r httpClient
While most people will use vCenter etc to manage hosts, for anyone with a stand alone host, or in a home lab this is a handy command to quickly patch something.
What if I get the following error?
[MetadataDownloadError] Could not download from depot at https://dl.broadcom.com/TOKEN_GOES_HERE/PROD/COMP/ESX_HOST/main/vmw-depot-index.xml, skipping (('https://dl.broadcom.com/TOKEN_GOES_HERE/PROD/COMP/ESX_HOST/main/vmw-depot-index.xml', '', 'HTTP Error 404: Not Found')) url = https://dl.broadcom.com/TOKEN_GOES_HERE/PROD/COMP/ESX_HOST/main/vmw-depot-index.xml Please refer to the log file for more details.
You forgot to replace the placeholder for the token code I put in the syntax. 🙂
If it runs successfully you should be greeted with a big wall of text.
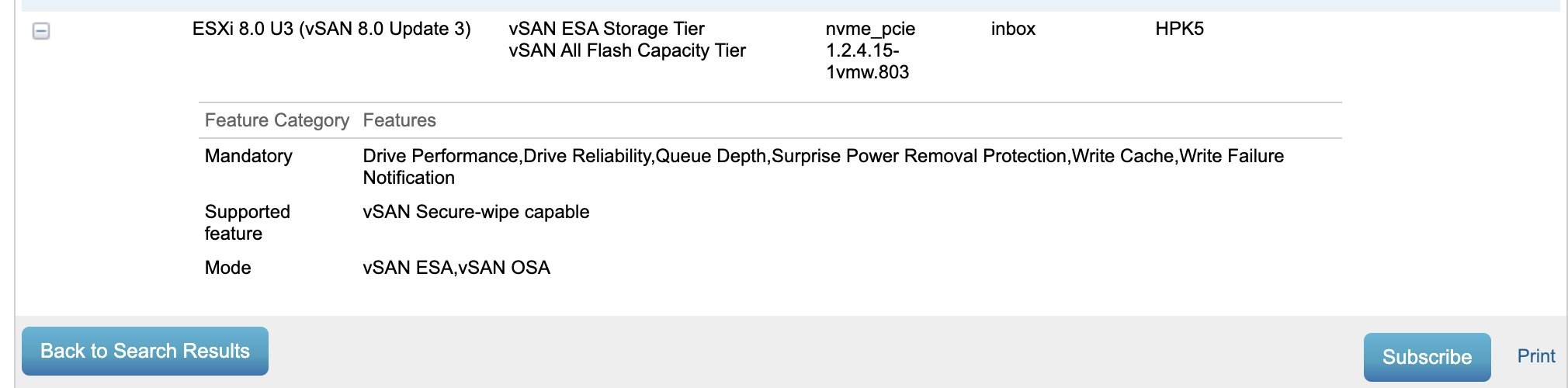
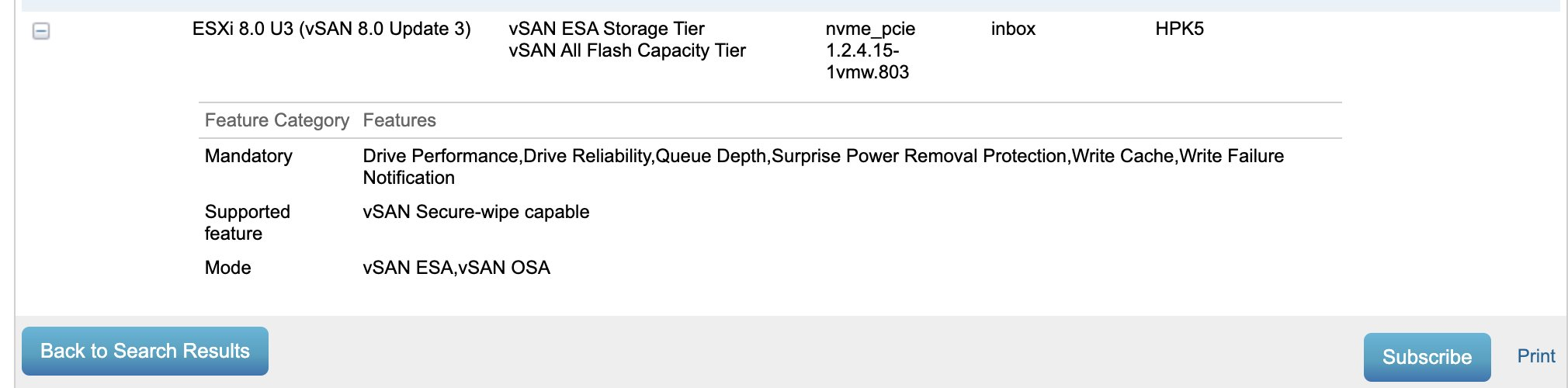
Note while you are here click the “Subscribe” button in the bottom corner for updates to changes on the VCG and note this uses the inbox driver, with the newest supported firmware being HPK5. Also certified for ESA.
While I”m here I’ll check what that firmware version fixed. Looks fairly serious from a stability basis so I’ll make sure to use HPE’s HSM + vLCM to patc this drive to the current firmware.
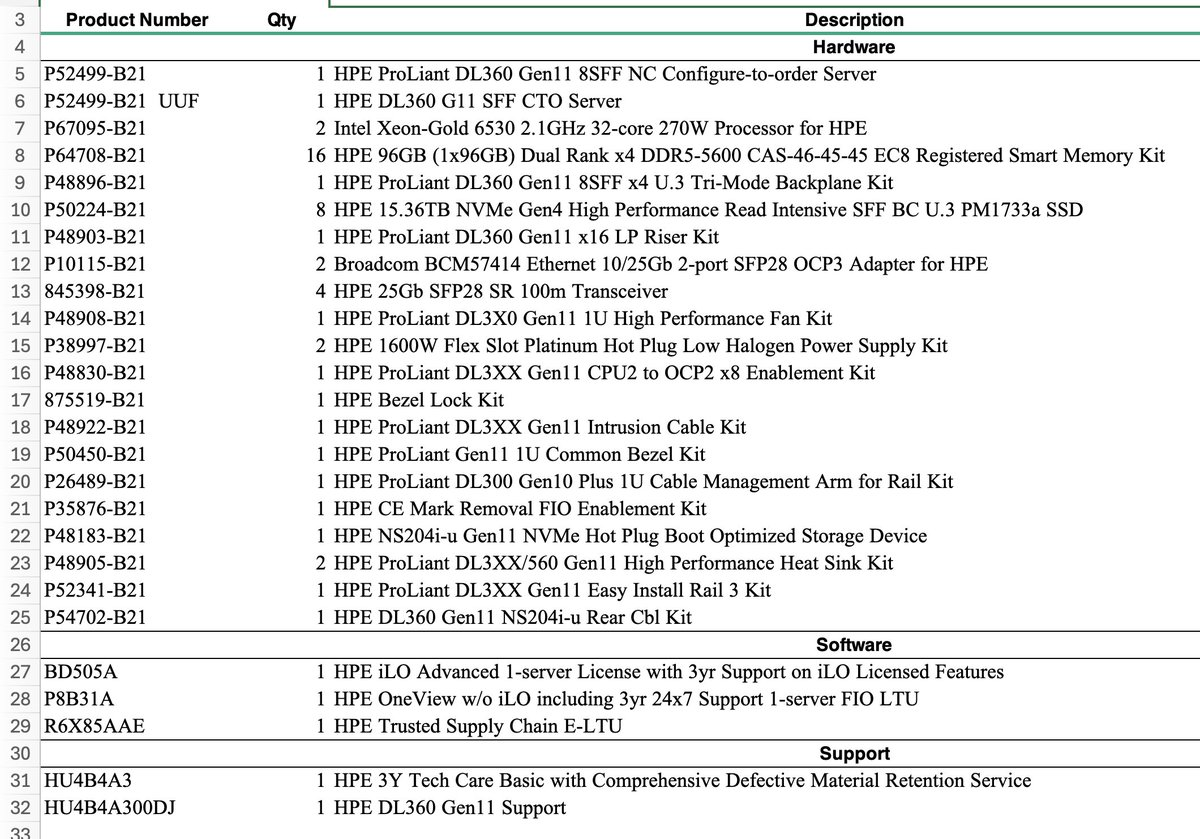
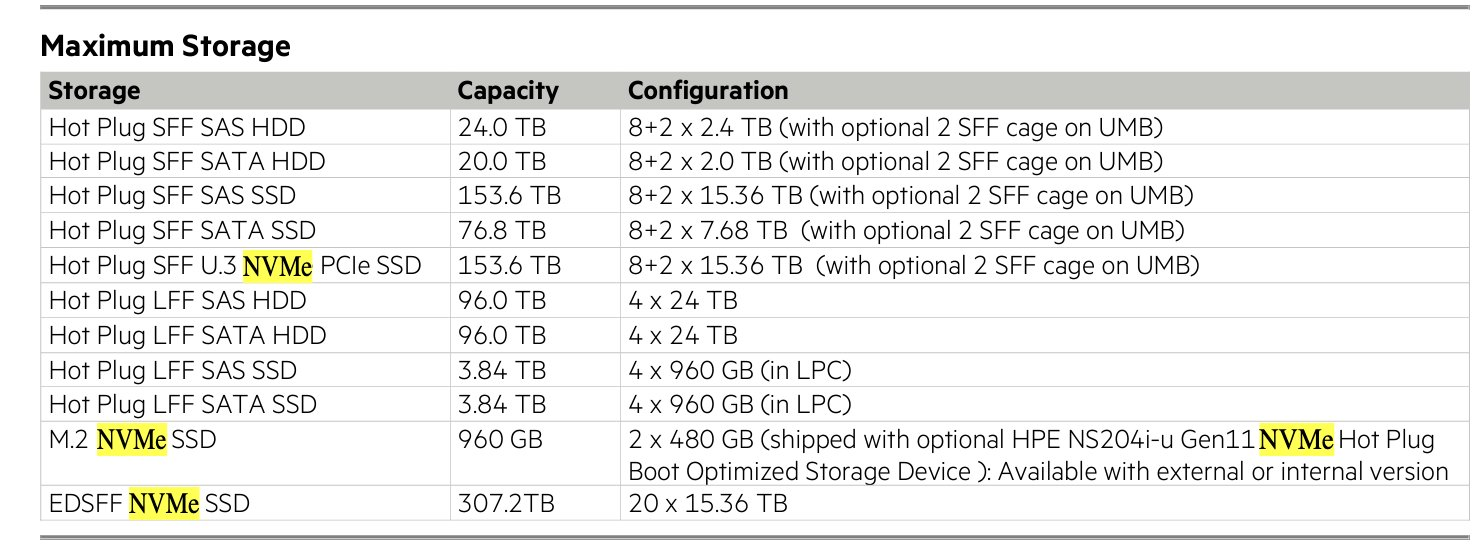
Next up let’s look at P48896-B21: 1 HPE ProLiant DL360 Gen11 8SFF x4 U.3 Tri-Mode Backplane Kit
So this is the drive cage you NEED to use NVMe in a DL360 as it gives 4 PCI-E lanes to each drive (vs the cheaper basic one that only is 1x and only supports SATA in pass through.
Looking at the QuickSpecs There are a 3 other options for ESA vSAN.
LFF 3.5”: Can’t do NVMe pass through.
24G x 1 NVMe/SAS U3. Can’t do NVMe pass through, and frankly will underperform with NVMe drives even if used for RAID.
20EDSFF – Supported for ESA.
LFF Server (not supported for VSAN ESA)
Rambling out loud, I think E3 form factor stuff is a better play in the long term as it allows more density. 2.5” SFF really is going to end up legacy for greenfield that shouldn’t be needed.
Note the E3 config will support 300TB, 2x the SFF ones. (Please go 100Gbps networking if your doing something that dense!)
We do have a NS204i-u, but that is only for a pair of M.2 boot devices (and a GREAT idea for boot, stop doing SD card, boot from SAN weird stuff!). This WILL NOT and cannot be used with the larger SFF or E3 format drives (and that’s a good thing!).
Next up what’s missing. There is NOT a RAID controller (Generally starts with MR or SR). If there’s one of these the NVMe drives will potentially be cabled to it (and that’s bad, and not supported by vSAN ESA).
Per the quickspecs:
“Includes Direct Access cables and backplane power cables. Drive cages will be connected to Motherboard (Direct Attach) if no Internal controller is selected. Direct Attach is capable of supporting all the drives (SATA or NVMe).”
Now I’ll note this BOM only supports 8 drives, but if your willing to not have an optical drives, or a front USB/Display port There is a way to get 2 more cabled in:
One other BOM review item. They went 4 x 25Gbps. If you don’t already have 25Gbps TOR switches I would honestly go 2 x 100Gbps. It’s about 20% more cost all in with cables and optics, but it’s 2x the bandwidth and the rack will look prettier.
There’s also not an Intel VROC license/config item on here. This is a “software(ish) RAID option for NVMe. We don’t need/want this for vSAN ESA. In theory there might be a way to use this for a boot device but use the NS controller instead for now.
In general talk to your HPE Solution architects, their quoting tools should be able to help (HPE always had really good channel tools), if possible start with a ReadyNode/vSAN ESA option to lock out bad choices.
Thanks to Dan R for providing me some insight into this.
I’m sure @plankers already noticed the lack of a TPM.
It’s now embedded, and disabled if your servers is going to China.
I’m glad HPE stoped making this an removable option.
nother point, for anyone playing with the new memory Tiering, you also are going to want that cabled this way, as that feature is not supported through a RAID controller either.
What Happens When I Change the Key Provider, KMIP, Native Key Provider, NKP, for vSAN Encryption? vSAN encryption provides easy, fast data at rest encryption, as well as a unique data in transit encryption option. Data at rest encryption specifically requires a key provider to be used. This can either be an external KIMP provider (Certification list found here), as well as a native key provider option that is bundled with the vCenter Server. For various reasons a customer may wish to switch keys, or even switch to keys provided by a different key provider.
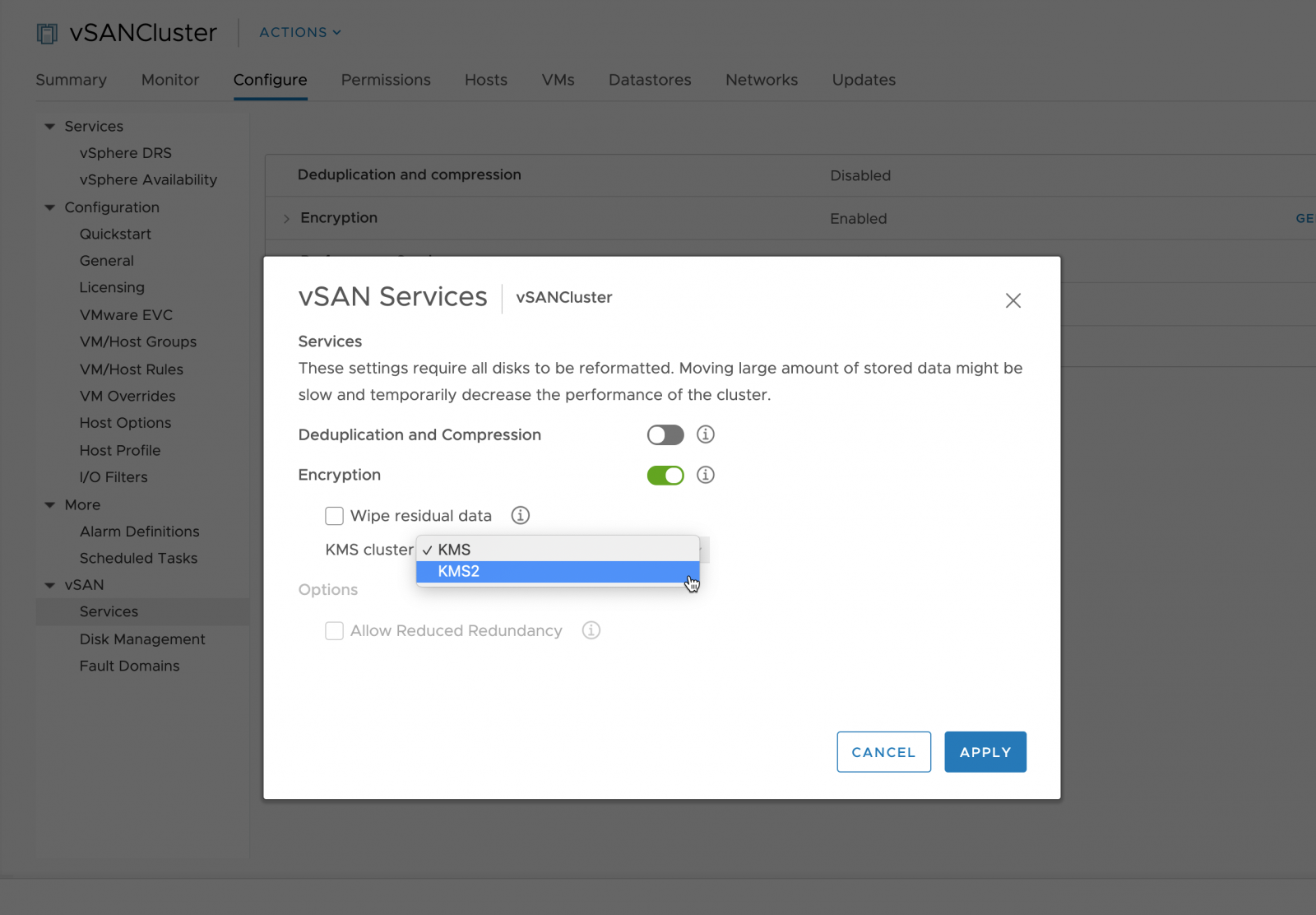
“Can I change the Key provider, KMIP, Native Key Provider, NKP, for vSAN/vSphere Encryption?” The short response is “yes” this is quick/easy and supported. Within the UI you will change to the new keys used, anda shallow rekey operation will kick-off.
What happens when I change the keys? Changing the keys is a shallow rekey operation, NOT a deep rekey operation. What does that mean? A deep key swaps the KEK and DEK and forces a re-write of all of the data to the disk groups one at a time,this kind of operation can take a rather long time. A shallow re-key is rather quick as it will create new anew KEK for the cluster and push it to the hosts. Each device’s DEK will then be re-wrapped with the new KEK+DEK combination.
The full process to change the keys from within the UI is as follows:
The initial KMS configuration is in place
The administrator selects an alternate KMS Cluster
The new KMS configuration is pushed to the vSAN hosts
A new host key is generated
vSAN performs a Shallow Rekey
More information on vSAN Encryption operations can be found in the VSAN Encryption Services Tech note.
Auto-Policy Remediation Enhancements for the ESA in vSAN 8 U2
vSAN 8 U1 introduced a new Auto-Policy Management feature that helps administrators run their ESA clusters with the optimal level of resilience and efficiency. This helps takes the guesswork and documentation consultation after deploying or expanding a cluster on what is the most optimal policy configuration. In vSAN 8 U2, we’ve made this feature even more capable.
Background
Data housed in a vSAN datastore is always stored in accordance with an assigned storage policy, which prescribes a level of data resilience and other settings. The assigned storage policy could be manually created, or a default storage policy created by vSAN. Past versions of vSAN used a single “vSAN Default Storage Policy” stored on the managing vCenter Server to serve as the policy to use if another policy wasn’t defined and applied by an administrator. Since this single policy was set as the default policy for all vSAN clusters managed by the vCenter Server, it used settings such as a failures to tolerate of 1 (FTT=1) using simple RAID-1 mirroring to be as compatible as possible with the size and the capabilities of the cluster.This meant that the default storage policy wasn’t always optimally configured for a given cluster. The types, sizes, and other characteristics of a cluster might be very different. Changing a policy rule optimized for one cluster may not be ideal, or even compatible with another cluster. We wanted to address this, especially since the ESA eliminates compromises in performance between RAID-1 and RAID-5/6.
Auto-Policy Management for ESA
Configuration of the policy is covered in the 8U1 feature blog here. Once configured, this will automatically create the relevant SPBM policy for the cluster.
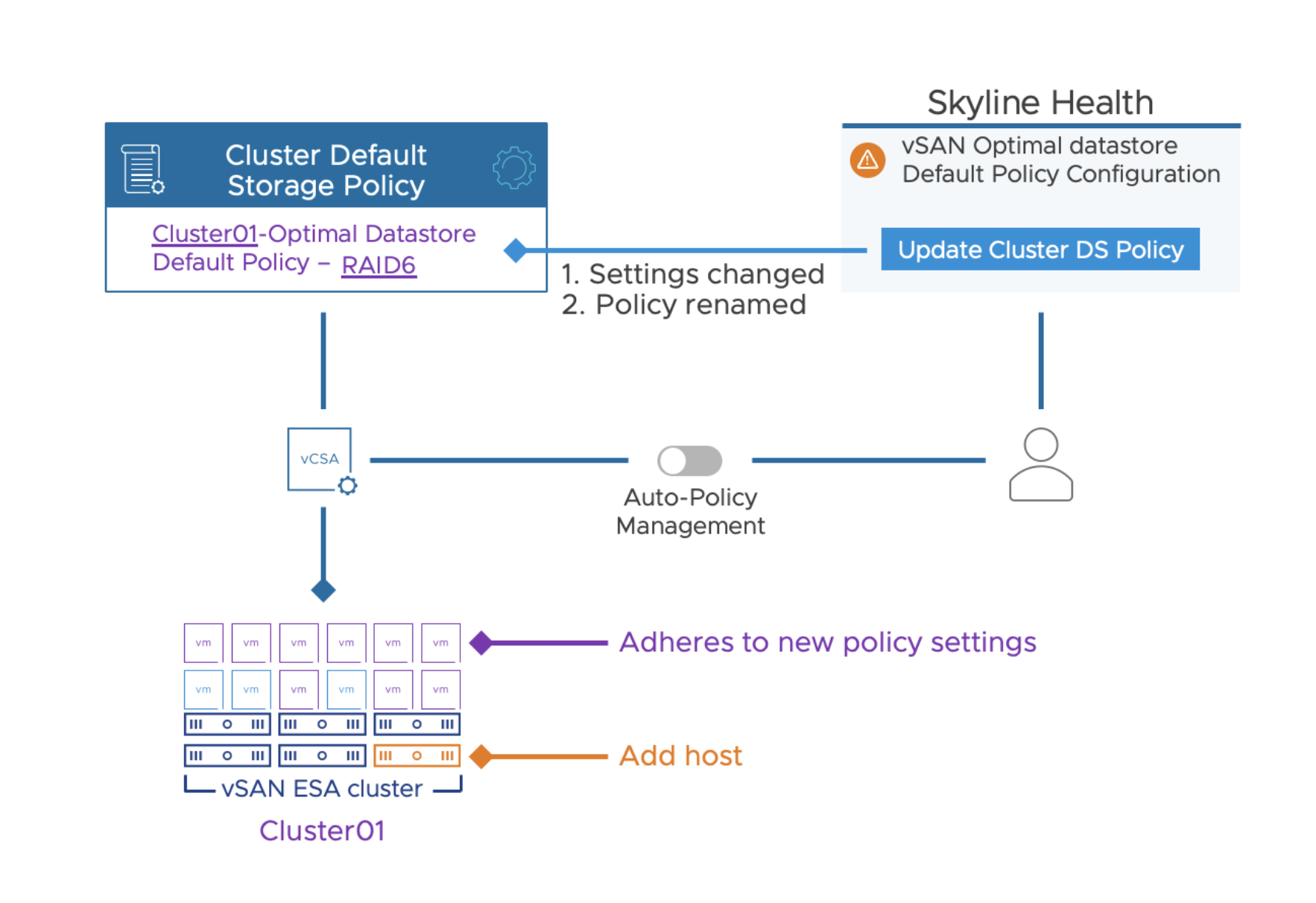
Upon the addition or removal of a host from a cluster, the Auto-Policy Management feature will evaluate if the optimized default storage policy needs to be adjusted. If vSAN identifies the need to change the optimized default storage policy, it does so by providing a simple button in the triggered health finding to change the affected storage policy, at which time it will reconfigure the cluster-specific default storage policy with the new optimized policy settings. It will also rename the policy to reflect the newly suggested settings. This guided approach is intuitive, and simple for administrators to know their VM storage policies are optimally configured for their cluster. This change specifically addresses improved behavior for ongoing adjustments in the cluster. Upon a change to the cluster size, Instead of creating a new policy (as it did in vSAN 8 U1), the Auto-Policy Management feature will change the existing, cluster specific storage policy.
Upon a reconfiguration of the Auto-Policy generated storage policy, the automatically generated name will also be adjusted. For example, in a 5-host standard vSAN cluster without host rebuild reserve enabled, the auto-policy management feature will create a RAID-5 storage policy, and use the name of: “cluster-name – Optimal Datastore Default Policy – RAID5”
If an additional host is added to the cluster, after a 24 hour period, the following events will occur:
The Administrator will be prompted with an optional button “Update Cluster DS Policy.”
This will trigger two events The existing policy is changed to RAID-6 The existing policy’s name is changed to “cluster-name – Optimal Datastore Default Policy – RAID6”
As described in the steps above, vSAN 8 U2 still does not automatically change the policy without their knowledge. The difference with vSAN 8 U2 is that upon a change of a host count in a cluster, we not only suggest the change, but upon an administrator manually click on the button “Update Cluster DS Policy” we will make this adjustment for them. A host in maintenance mode does not impact this health finding. The number of hosts in a cluster are defined by those that have been joined in the cluster
Configuration Logic for Optimized Storage Policy for Cluster
The policy settings the optimized storage policy uses are based on the type of cluster, the number of hosts in a cluster, and if the Host Rebuild Reserve (HRR) capacity management feature is enabled on the cluster. A change to any one of the three will result in vSAN making a suggested adjustment to the cluster-specific, optimized storage policy. Note that the Auto-Policy Management feature is currently not supported when using the vSAN Fault Domains feature.
Standard vSAN clusters (with Host Rebuild Reserve turned off):
3 hosts without HRR : FTT=1 using RAID-1
4 hosts without HRR: FTT=1 using RAID-5 (2+1)
5 hosts without HRR: FTT=1 using RAID-5 (2+1)
6 or more hosts without HRR: FTT=2 using RAID-6 (4+2)
Standard vSAN clusters (with Host Rebuild Reserve enabled)
3 hosts with HRR: (HRR not supported with 3 hosts)
4 hosts with HRR: FTT=1 using RAID-1
5 hosts with HRR: FTT=1 using RAID-5 (2+1)
6 hosts with HRR: FTT=1 using RAID-5 (4+1)
7 or more hosts with HRR: FTT=2 using RAID-6 (4+2)
vSAN Stretched clusters
3 data hosts at each site: Site level mirroring with FTT=1 using RAID-1 mirroring for a secondary level of resilience
4 hosts at each site: Site level mirroring with FTT=1 using RAID-5 (2+1) for secondary level of resilience.
5 hosts at each site: Site level mirroring with FTT=1 using RAID-5 (2+1) for secondary level of resilience.
6 or more hosts at each site: Site level mirroring with FTT=2 using RAID-6 (4+2) for a secondary level of resilience.
vSAN 2-Node clusters:
2 data hosts: Host level mirroring using RAID-1
Summary
The new improved Auto-Policy Management feature in vSAN 8 U2 serves as a building block to make vSAN ESA clusters even more intelligent, and easier to use. It gives our customers confidence that resilience settings for their environment are optimally configured.
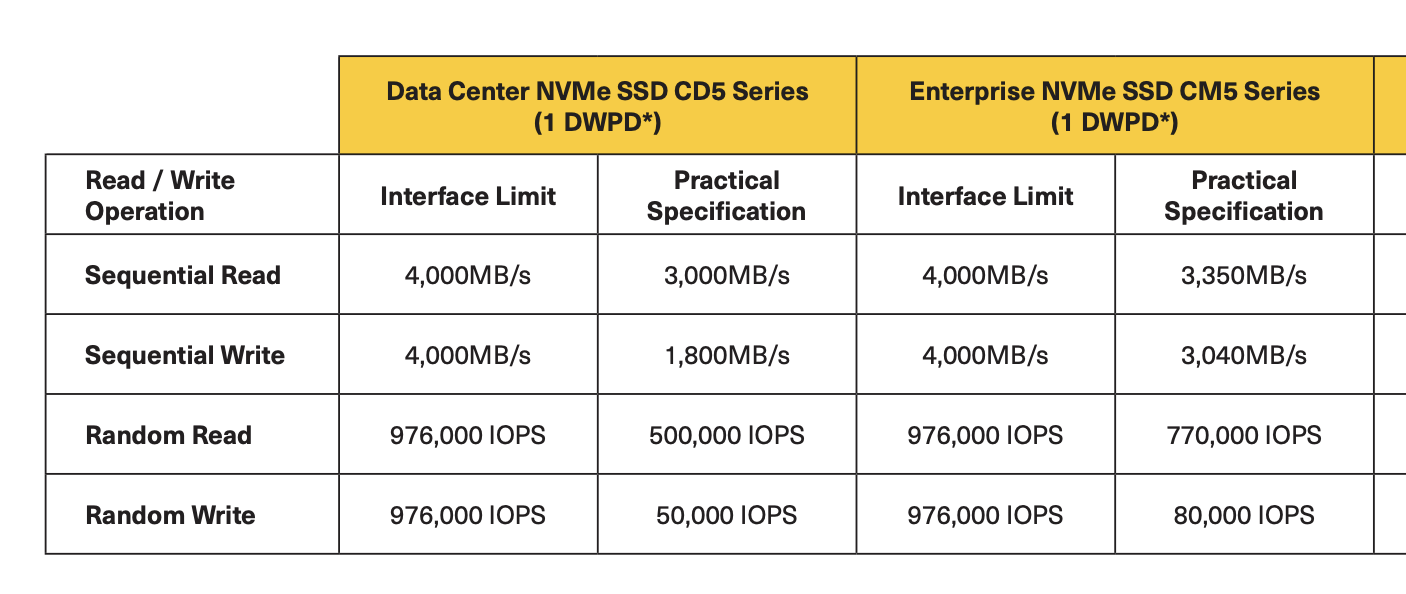
It’s come to my attention that a lot of people shopping storage really don’t know what to expect for NVMe server drives. Also looking at some quotes recently I can say some of you are getting great prices, and some of you are getting…. Well a quote…
I’m seeing discounted prices in the 12 cents (Read Intensive, Datacenter Class drives) to closer to 30 cents (Mixed use, fancier Enterprsie class drives) depending on volume and order. I’m also seeing some outliers (OEMs charging 60 cents per GB?!?!). Seeing better/worse pricing? message me on twitter @Lost_Signal.
I did look around the ecosystem and see one seller closing in on 10 cents per GB for one of the Samsung drives in an OEM caddy.
While DRAM and other component costs matter, vSAN Storage only clusters with dense nodes (200-300TiBs of NVMe) will typically see over 80% of the hardware BOM be the NVMe drives. This is driving a lot of focus on drive pricing and some awkward questions with server sales/accounting teams trying to explain charging 4-5x the going rate for drives.
So why is there such a difference in drive prices?
Drive Types
First off there’s a number of critera that can influence the price of a drive:
What’s the endurance? Mixed-Use (3 drive write per day) drives are what vSAN ESA started with, but it is worth noting they cost more. How much more? ~20% more than Read Intensive drives that only support 1 DWPD. Do I need Mixed use? In short most of you do not, but you should check your change rate, or write rate. Very high throughput data warehouses doing tons of ETLs or large automation farms may see the need to pay the fancier drive that will last longer, and likely have better high end write throughput. I would expect 90% of clusters can use Read Intensive drives though at this point.
Enterprise or Datacenter class TLC drives – Much like “value SAS” before a cheaper slightly less featured (single port vs. 2 port which does NOT matter inside a server), slightly less performant class of NVMe drive is showing up on quotes. I’m so far a fan, for anything but ultra high write throughput workloads it should save you some money. It’s positioned well to replace SATA. and furthers the argument that vSAN OSA is a legacy platform, and ESA should be all new builds. Speaking to one vendor recently they were skeptical of the need for QLC NAND when the cheaper “Datacenter class” TLC can hit pretty solid price points without some of the performance and endurance limits that QLC currently faces (To be fair, we all said the same thing about SLC, and MLC and TLC before, so in the long run I”m sure we will end up on QLC and PLC eventually).
SAS/SATAare not supported by vSAN ESA, but frankly I’m seeing prices at the same or frankly worse for similarish SAS drives. I don’t expect SAS/SATA to show up in the datacenter much going forward beyond maybe M.2 boot devices.
Price List and Discounting
Price list price. Note there are two factors at play here. A vendor will have a list price that is HIGHLY inflated (think 10-12x the component cost to them or even a normal person purchasing that device). These price lists are not consistent vendor to vendor. Price lists are not always universal, they might be per country, by quarter, by contract vehicle and by company. Negotiated price lists can do some weird things. vehicles that are not updated quarterly effectively mean you have committed to worse prices over time (As market prices go down). Also older price lists will not include newer drives or SKUs that are cheaper, sometimes forcing customers to purchase older servers/drives etc at higher cost.
Discount % – When I ask people what they pay for drives or servers they often reply with a discount percent, with a slight bit of excitement and zero context. This is a bit like me telling people I paid 30% off for an air filter yesterday. (30% of WHAT?) Discussing discount without knowing the price list markup is a bit like buying a car without knowing what currency you are negotiating in. Different OEMs have different blends of markup, and base discounts. One Tier 1 vendor OEM’s example of expected discounts are:
55% – Anyone with a pulse should get this discount. 65% – If you found a partner and they felt like making 20% off of you, this is your normal pricing for a small order from a small company. 75% – A reasonable normal discount 85% – A large order, or an order from a large company who does a lot of purchasing. 90%+ You bought a railcar sized order.
Some factors that can influence discount size:
Note Tier 2/3 OEMs tend to have much more “Street ready pricing” by default.
Some factors that can influence discount size
Size of deal – Larger orders can discount more.
Financial Shenanigans – Some server vendors are currently trying to operate as a SaaS companies in their financial reporting to wallstreet. As part of this cosplaying as a subscription service, they will only quote sane discounts/prices if you structure the deal as a subscription deal. They may require this have a cloud connected component that in reality has no real value, but I assure you is required by auditors to comply with ASC 606 accounting regulations and totally isn’t dubiously stretching the line at the unique value requirements of the cloud bits. If you do not want a quote that costs 3x what it should, and would like servers delivered this year instead of 2026, I suggest you roll your eyes, and ask for that new cloud thing!.
Competitive pressure – Competitive deals (meaning there is another vendor quoting servers or drives) typically unlocks 10-30% better pricing for the sales team. If you NEVER quote anyone else (even as a benchmark) you will discover your pricing power even at scale slowly atrophies over time. Seriously, go invite Lenovo, or Hitachi, Fujitsu or some other vendor to throw a quote at the wall. Even if you likely plan to stick with your existing OEM, you will find this helps keep pricing a bit more honest.
Vendor doesn’t want to sell you the drives(because they want to sell something else!)– This one is weird, but if you are asking a VAR/Server vendor who also sells storage to quote you NVMe drives for vSAN… They may have a perverse incentive to mis-price them so they can sell you a higher margin external storage array. Server components (especially to partners, I used to work for one!) tend to offer less margin, and vendor sales reps may have quota buckets they need to fill in storage. This reminds me of the wise words of Eric.
Common factors for higher prices
“The customer gets ONE of the votes on what they get to buy” – Enterprise Storage sales rep who I saw make 700K in commission.
You specified a very specific drive they don’t have in stock – Vendors have gotten increasingly annoyed with being forced to stock like for like parts for replacement, and supply chain management of 40 different NVMe drive SKUs (performance, encryption, endurance, capacity variables) has allowed their supply chain guys to offer discounts for “Agnostic SKUs” (where you get something that meets the spec). While I am partial to some specific drive SKUs this can cost you anywhere from 20% to 100% as well as delays in shipping. By discounting drives they have to sell and want to sell they can make sure the server gets sold in THIS quarter so they can book revenue now.
Sandbagging, SPIFFSand other odd sales behaviors – People who sell most of the time want to help the customer solve a problem. That said they also are driven by a long list of various incentives to sell specific things at specific times. This is referred to as “Coin-Operated” behavior. Sandbagging is a term used when a sales team purposely slows down a deal. This could be because they have hit a ceiling on how much commission they can earn, or accelerators to their commission. SPIFFs are one off payments for selling specific things, often paid not by the sales teams employer but a manufacturer or partner directly. It frankly always felt strange to have a storage vendor trying to pay me in Visa Gift cards on the side (I generally refused these, as it felt like a illicit transaction) but it does happen.
Meet Otto. He’s a rescue who’s I guess around 10 years old, weighs 11-12 pounds and likes children and all people.
His likes are naps, sunning himself in the yard, and making me take him on 2-3 walks a day to keep me in shape.
He is weirdly quiet (Doesn’t bark), and doesn’t really make a mess or scratch at things.
I was told by my agent to attach a photo for landlords to see to applications, and finding some of their platforms don’t make this an option, will just embed a link to this blog post. If you see him on a greenbelt trail you or your children are welcome to pet him, he’s extremely harmless.
Now, the real details are a bit more complicated than that. It’s possible to use the 8SFF 4x U.3 TriMode (not x1) backplane kit, but only if the server was built out with only NVMe drives, and no RAID controller/Smart Array. Personally I’d build of of E.3 drives. For a full BOM review and a bit more detail check out this twitter thread on the topic where I go step by step through the BOM outlining what’s on it, why and what’s missing.
A quick blog post as this came up recently. Someone who was looking t NVMoF with their storage was asking how do they configure a similar end to end vSAN NVMe I/O path that avoids SCSI or serial I/O queues.
Why would you want this? NVMe in general uses significantly less CPU per IOP compared to SCSI, has simpler hardware requirements commonly (no HBA needed), and can deliver higher throughput and IOPS at lower latency using parallel queuing.
Configure the vNVMe adapter instead of the vSCSI or LSI Buslogic etc. controllers.
(Optional) – Want to shed the bonds of TCP and lower networking overhead? Consider configuring vSAN RDMA (RCoE). This does require some specific configuration to implement, and is not required but for customers pushing the limits of 100Gbps in throughput this is something to consider.
Deploy the newest vSAN version. The vSAN I/O path has seen a number of improvements even since 8.0GA that make it important to upgrade to maximize performance.
To get started adda. NVMe Controller to your virtual machines, and make sure VMtools is installed in the guest OS of your templates.
Note you can Migrate existing VMDKs to vNVMe (I recommend doing this with the VM powered off). Also before you do this you will want to install VMtools (So you have the VMware paravirtual NVMe controller driver installed).
So it’s time to stand up your new VMware cluster. You have reviewed your compute and storage requirements, and have picked hosts with 1-2TB of RAM, 100-300TB of storage, 32 core x 2 socket CPUs and are ready to begin that important consolidation project. You will be consolidating 3:1 from older hosts and before you deploy you get one additional requirement.
Networking Team: “We can only provision 2 x 10Gbps to each host”
You ask why? and get a number of $REASONS.
Looking at average utilization for the month it was below 10Gbps.
25G/100Gbps cables and optics sounds expensive.
Faster speeds seem unnatural and scary.
Networking speed is a luxury for people who have Tigers on gold leashes, and we needed to save money somewhere.
There is no benefit to operations.
We are not due to replace our top of rack switches until 2034.
Now all of these are bad reasons, but we will walk through them starting with the first one today.
What is the impact of slow networking on my host?
Now you may think that slow networking is a storage team problem, but the impacts of undersized networking can impact a lot of differnt things. Other issues to expect to run into from undersized networking:
1. Slower vMotions, higher stun times, and longer host evacuations will be caused by slower networking. As you stuff more and more bandwidth intensive traffic on the same link the greater contention for host evacuations. This impacts maintenance mode operations and data resynchronization times.
2. Slow Backup and restore. While backups may be slower, we can somewhat cheat slow networking using CBT (Changed Block Tracking) and only doing forever incremental. Slow large data restore operations are the biggest concern for undersized networking. After a large scale failure or ransomware attack you may discover that rehydrated large amounts of data over 10Gbps is a lot slower than over 100Gbps. There is always a bottleneck in backup and restore speed, but the network is generally the cheapest resource to fix. You can try to mitigate this with scale out backup repositories, and using more data movers/proxys’, and more hosts and SAN ports, but in the end this ends up being far less cost effective than upgrading the network to 25/50/100Gbps.
3. Slower networking for storage, manifests itself in worse storage performance, specifically on large throughput operations, but also short microbursts where latency will creep up. Keep in mind that 10Gbps sounds like a lot but that is *per second*. If you are trying to get a large block of data in under 5ms that time window a single port can only move 6.25MB. As we try to pull average latencies down lower we need to be cognizant of what that link speed means for burst requests. Overtaxed network storage will often mask the true peak demand as back preasure and latency creep in. Pete has a great blog on this topic.
4. Slower large batch operations. Migrations, Database transform and load operations, and other batch jobs are often bandwidth constrained. You the operator may just see this as a 1-2 minute “bip” but making that 1-2 minute reponse in an end user application turn into a 10-20 second response can significantly improve the user experience of your application.
5. Tail latency. Applications with complicated chains of requests often are fundamentally bound by the one outlier in response times. Faster networking reduces the chance of contention somewhere in that 14 layer micro-service application the devops team has built.
6. Limitations on storage density. For HCI or any scale out storage system you will want adequate network bandwidth to handle node failure gracefully. vSAN has a number of tricks to reduce this impact (ESA compresses network resync, durability components) but at the end of the day you will not want 300TB in a vSAN/Ceph/Gluster/Minio node on a 10Gbps connection. There is a insidious feedback loop of slow networking is that it forces expensive, design decisions (lower density hosts and more of them), that often masks the need for faster networking. Even non-scale out platforms eventually will hit walls on density. a Monolithic storage array can scale to a lot more density and run wider fan out ratios using 100Gbps ethernet than 10Gbps ethernet.
Let us first dig into the first and most common objection to upgrading the network.
“Looking at average utilization for the month it was below 10Gbps”
How do you we as architects respond to this statement?
Networks are bursty is my short response to this. Pete Koehler calls this “The curse of averages”. Most of the tooling people use to make this statement is SNMP monitoring tooling that polls every few minutes. This apprach is find for slowly changing things like temperature, or binary health events like “is power supply dead?”. Unfortuently for networking, a packet buffer can fill up and cause back preasure and congestion in as short as 100ms, and SNMP polling every 5 minutes is not going to cut it for this. Inversely context around WHEN a network is saturated is important. If the network is saturated in the middle of the night when backups or databse maintenance or ETL runs I might not actually care. Using an average with a poor samplying frequency of times when I do and do not care about congestion is about the worst way to make a design decision possibly.
There are ways to understand congestion and it’s impacts. You may notice on the outliers of storage latency polling that there is corresponding high networking utilization at the same time. You can also get smarter about monitoring and have switches deliver syslog information about buffer exhaustion to your operations tool and overlay this with other metrics like high CPU usage, or high storage latency to understand the impact on slow undersized networking. (Screenshot of LogInsight generating an alarm).
Why is observability on networking often bad?
Operations teams are often a lot more blind to networking limitations than they realize. Now it’s true this tooling will never be perfect as there becomes some challenges trying to get a 100% perfect network monitoring.
Why not Just SNMP poll every 100ms?
The more frequent the polling on monitoring the more likely the monitoring itself starts to create overhead that impacts the networking devices or hosts themselves. Anyone who has turned on debug logging on a switch and crashed it should understand this. Modern efforts to reduce it (dedicated ASIC functions for observability, seperation of observability from the data plane in switches) do exist. It is worth noting vSAN hsa a network diagnostic mode that goes down to 1 second, which is pretty good for acute troubleshooting.
Can we just monitor links smarter?
Physical fiber taps that sit in line and sniff/process the size/shape/function/latency of every packet do exist. Virtual instruments was a company who did this. People who worked there told me “Storage arrays and networks lie a lot” but the cost of deploying fiber taps, and dedicated monitoring appliances per rack often exceeds just throwing more merchant silicon at the problem and upgrading the network to 100Gbps.
What tooling exists today?
Even driven tooling is often going to be the best way to detect network saturation. Newer ASICs and APIs exist, as well as siply having the switch shoot a syslog event when congestion is happening can help you overlay networking problems with application issues. VMware Cloud Foundation’s built in Log analytics tooling can help with this, and can overal the VCF Operations performance graphs to get a better understanding of when the network is causing issues.
Can we Just squeeze traffic down the 10Gbps better?
A few attempts have been made to “make 10Gbps work”. The reality is I have seen hosts that could deliver 120K IOPS of storage performance crippled down to 30K IOPS and so forth because of slow networking but we can review ways to make 10Gbps better…
Clever QoS to make slower networks viable?
Years ago CoS/DSCP were commonly used in the past to protect voice traffic over LANs or MPLS, and while they do exist in the datacenter most customers rarely use them in top of rack. Segmenting traffic per VLAN, making sure you don’t discover bugs in implementations, making sure tags are honored end to end is a lot of operational work. While the vDS supports this, and people may perform it on a per port group basis for storage, generally NIOC shaping traffic is about as far as most people operationally want to get involved in going down this path.
Smarter Switch ASICS
Clever buffer mangagement: “Elephant traps” (dropping of large packets to speed up smaller mice packets), and shared buffer management often worked to prevent one bursty flow, or one large packet from hogging all the resources. This was common on some of the earlier Nexus switches, and I’m sure was great if you had mixes of real time voice and buffered streaming video on your switch but frankly is highly problematic for storage flows that NEED to arrive in order.
Deeper Buffers Switches?
The other side of this coin was moving from swith ASICS with 12 or 32MB to multi-GB buffers. These “ultra deep buffer switches” could help mitigate some port over-runs and reduce the need for drops. VMware and others advocated for them for storage traffic and vSAN. With 10Gbps moving from the lower end Trident to the higher end Jericho ASICs we did see much better handling of micro-bursts, and even sustained workloads. TCP incast was mitigated. As 25Gbps came out though, we saw only a few niche switches configured this way and the pricing on them frankly was so close to 100Gbps that just deploying a faster pipe from point A to point B has proven to be more cost effective than trying to put a bigger bucket under the leak in the roof.
What does faster networking cost?
While some of us may remember 100Gbps ports costing $1000+ a port, networking has gotten a lot cheaper. The same commodity ASICs (Trident 3, Jericho, Tomahawk) power the most common top of rack leaf and spine switches in the datacenter today. Interestingly enough you can even now buy your hardware from one vendor, and switch OS or SDN management overlay for SONIC.
While vendors will try to charge large amounts for branded optics, All in one cables (called AIO) and passive TwinAx copper cables can often be purchased for $15-100 depending on length, and temperature tolerance requirements. These cables remove the need to purchase an optic, and reduce issues with dust and port errors by being “welded shut” against the SFP28/QSFP copper transceiver.
$15 – $30 for 25Gbps passive cables
TINA – There is no Alternative (to faster networking)
The future is increasingly moving core datacenter performance intensive workloads to 100Gbps, with 25Gbps for smaller stacks (and possible 50Gbps even replacing that soon). The cost economics are shifting there, and the various tricks to squeeze more out of 10Gbps feels a bit like squeezing a single lemon to try to make 10 gallons of lemonade. “The Juice isn’t worth the squeeze.” While many of the above problems of slow networking can be mitigated with more hosts, lower performance expectations, longer operational windows, eventually it becomes clear that upgrading the network is more cost effective than throwing server hardware and time at a bad network.
A while back I was asking engineering how they tested RDMA between hosts and stumbled upon RDTBench. This is a traffic generator, where you configure one host to act as a “server” and 1 to several hosts to act as clients communicating with it. This is a great tool for testing networking throughput before production use of a host, as well as validating RDMA configurations as it can be configured to generate vSAN RDMA traffic. Pings and IPERF are great, but being able to simulate RDT (vSAN protocol) traffic has it’s advantages.
RDT Bench does manifest itself as traffic on the vSAN Performance service host networking graphs
How do I run it? You need to run it on two different hosts. One host will need to be configured to act as a client (by default it runs as a server). For the server I commonly use the -b flag to make it run bi-bidirectionally on the transport. -p rdma will run it in RDMA mode to test RDMA.
If RDMA is not working, go ahead and turn vSAN RDMA on (cluster, config, networking).
vSAN will “fail safe” back to TCP, but tell you what is missing from your configuration.
./rdtbench -h will provide the full list of command help.
For now this tool primarily exists for engineering (used for RDMA NIC validation) as well as support (as a more realistic alternative to IPERF), but I’m curious how we can incorporate it into other workflows for testing the health of a cluster.