According to a study by Google, The annual incidence of uncorrectable errors was 1.3% per machine and 0.22% per DIMM. This rate rises to 1.7–2.3% after seeing corrected errors. Hard errors are caused by physical factors, such as excessive temperature variation, voltage stress, or physical stress brought upon the memory bits. Soft errors are random bit flips, typically associated with alpha particle radiation, solar winds and are correctable.

As the number of DIMMs and density of them increases, I suspect this only gets worse and rapidly approaches 100% if I have something important to work on.

Now, what happens with a VMware host, when the CPU detects unrecoverable errors for memory? This depends on who gets the bad bit:
-VMkernel: Crash (i.e. PSOD) the ESX host unless the kernel is within MCE Safe context.
VMM: Kill the VM. (The Virtual Machine should restart).
User space: Kill the user world (Most processes can be restarted).
Now, what if we want some protection? It’s worth noting that using ECC memory provides some basic protection (A single bit randomly flipping), and more importantly, provides awareness against larger protections through active scrubbing (So we don’t commit corrupt data to disk). If we want to mitigate larger failures (Such as an entire memory device on a DIMM or a DIMM itself) we need to look for more advanced protection methods.
Memory Mirroring: This is pretty simple and fairly expensive. This involves mirroring all DIMMs, so that in the event of a DIMM failure the server will keep on running. This is only outmatched by more extreme triple-redundant quorum/voting systems used on spaceflight computers. This is only considered for mission-critical systems in extremely difficult to reach places (Submarine, diamond mine, etc).
Single Device Data Correction (SDDC) – Out of the normal 18 memory devices on a DIMM you kee 1 device for CRC and 1 device for parity. If one if the devices fails, its data can be reconstructed. This is called single-device data correction (SDDC). Think of this a bit like RAID 4 (dedicated parity device) with checksums stored on a dedicated device also rather than with the block of data. Note a +1 option, effectively keeps a “hot spare” device so that after a failure is mitigated, you can support another failure. For Intel The Silver/Bronze SKUs offer an adaptive variant called Adaptive Data Correction (ADC), at Bank granularity.
Double Device Data Correction (DDDC) – This is where things start to get fancy and weird. By combining two 4x DIMMs into the same memory channel you can run a double parity scheme across both devices. This comes with performance impacts (Memory throughput seems to be the main issue). This doesn’t seem to be recommended for high throughput applications (HPC).
Adaptive Double DRAM Device Correction (ADDDC) – New with the Intel Scalable series processors (2017), this enables the ability to avoid the performance pre-failure that the DDDC design normally imposes. Note this feature doesn’t work with 8x DIMM layouts (smaller 8 and 16GB DIMMs from what I’ve found). For Intel, the Platinum/Gold SKUs offer Adaptive Double DRAM Device Correction (ADDDC).
Other weird OEM options – You will find stuff like hot spare DIMMs, and exotic additional bit ECC, how often scrubbing is performed etc. Be careful with this stuff and talk to your OEM about the expected performance impact.
Address Range Partial Memory Mirroring – This is an intel specific technology with a bit of variety on the implementation depending on the OEM. Unlike DIMM mirroring (which is transparent) this requires a OS –> Firmware interface for the OS to be aware of. In this case this is what the vSphere reliable memory feature enables. How this works under the hood is kernel processes flagged for usage of this will use this memory and be protected up to and including a full DIMM failure. This feature requires Intel Xeon Platinum and Gold processors SKUs.
Let’s see what this looks like in VMware!
You can look up how much memory is considered reliable by using the ESXCLI hardware memory get command.
Before turning on feature:
[root@h2:~] esxcli hardware memory get
Physical Memory: 549657530368 Bytes
Reliable Memory: 0 Bytes
NUMA Node Count: 2
After turning it on:
[root@h2:~] esxcli hardware memory get
Physical Memory: 480938061824 Bytes
Reliable Memory: 68619579392 Bytes
NUMA Node Count: 2On boot I can see that a bit of DRAM has been borrowed for “reliable memory” (54GB). Given this is 1/8th of the memory in the host that is a trade off (12.5%) but it’s is something for mission critical applications that might be worth considering. Digging around 12.5% is normal for a 13Gen server. Note this memory overhead comes 100% out of the first NUMA node (ESXTOP will confirm this).

It’s worth noting that more than the kernel can use this feature. Virutal Machines can be configured for it by following KB2146595 and using the VMX flag sched.mem.reliable = "True"
If you reserve 30% or more of a CPU you could trip an alarm called “Significant imbalance between NUMA nodes detected”.
How much should be reserved? The guidance in 5.5 was for at least 3GB, but if virtual machines are using this, or extensive services are being used ona host more may be needed.
There is a bit of variety in the OEM implementations.
Dell – The servers I tested this with by default grab either 12.5% or 25% of my hosts memeory depending on if I use the fault resilient mode, or the NUMA fault resilient mode.

HPE – offers overs 4GB reservation or 10% or 20% of memory above 4 GB.

Lenovo – Offers Mirroring of 4GB.
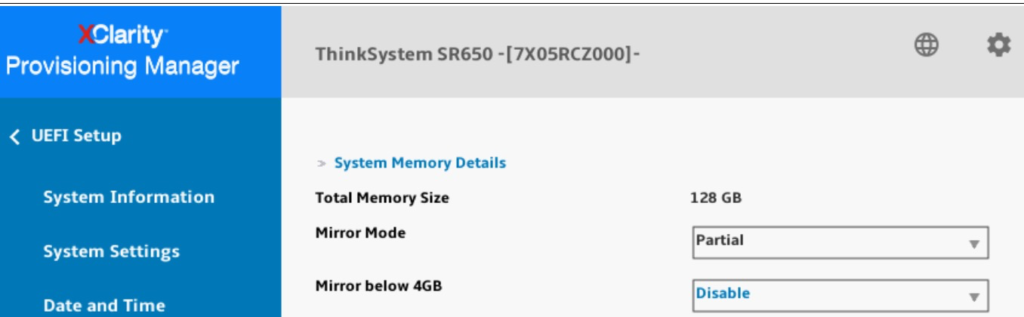
Fujitsu – Supports 4GB + %. Can be defined in UEFI (which makes me think other OEM’s might have unsuppoprted hacks to alter this in UEFI basd on Intel’s documentation).

SuperMicro – I found no mention of partial memory mirroring in their RAS guide. Note their RAS guide is a great read on the other parity based protections.
Should I configure reliable memory?
You fundamentally have to ask yourself a few questions:
- What am I paying for RAM, and what is the overhead going to be? In the case of the Dell functionality I tested it appears the BIOS is reserving 64GB. Looking at 3rd party memory prices this is going to run me in the us about $439. Looking at the spot price of memory recently it seems DRAM pricing is hitting new lows. Maybe it is worth sparing some to increase residency for mission critical clusters?
- What is my tolerance for a host failing from a bad DIMM? For this you need to look at your estimated DIMM failure rate, and consider the odds that something important in kernel space is crashed by the DIMM failure (most user world things and virtual machines will reboot if they hit a non-recoverable memory error). If this is Test/Dev I might not care, if I’m running an Oracle RAC cluster that backs the ERP for a fortune 50 company I might have more sensitivity.
- Is HA and/or application clustering “good enough protection?
- Should I extend this to Virtual Machines? The VMX flag allows configuration of virtual machines to attempt to fit into the reliable memory space. I’m not sure what happens when the host is given 64GB of reliable memory and I try configuring a 100GB reliable memory VM (More testing needed).
- Is 4GB good enough? Some platforms (HPE) offer the ability to configure 4GB or 4GB + xx%. By lowering what is protected (but lowering the cost overhead) a blend of risk mitigation and cost control may be “good enough” for many.
- Would I rather mirror a virtual machine between two hosts (SMP-FT) and just pay the extra overhead?
- Is there a particle accelerator or evil supervillain lab next door? If the server will be operating near a major source of alpha particle radiation it may be worth considering full mirroring (or shielding the server!)