Auto-Policy Remediation Enhancements for the ESA in vSAN 8 U2
vSAN 8 U1 introduced a new Auto-Policy Management feature that helps administrators run their ESA clusters with the optimal level of resilience and efficiency. This helps takes the guesswork and documentation consultation after deploying or expanding a cluster on what is the most optimal policy configuration. In vSAN 8 U2, we’ve made this feature even more capable.
Background
Data housed in a vSAN datastore is always stored in accordance with an assigned storage policy, which prescribes a level of data resilience and other settings. The assigned storage policy could be manually created, or a default storage policy created by vSAN. Past versions of vSAN used a single “vSAN Default Storage Policy” stored on the managing vCenter Server to serve as the policy to use if another policy wasn’t defined and applied by an administrator. Since this single policy was set as the default policy for all vSAN clusters managed by the vCenter Server, it used settings such as a failures to tolerate of 1 (FTT=1) using simple RAID-1 mirroring to be as compatible as possible with the size and the capabilities of the cluster.This meant that the default storage policy wasn’t always optimally configured for a given cluster. The types, sizes, and other characteristics of a cluster might be very different. Changing a policy rule optimized for one cluster may not be ideal, or even compatible with another cluster. We wanted to address this, especially since the ESA eliminates compromises in performance between RAID-1 and RAID-5/6.
Auto-Policy Management for ESA
Configuration of the policy is covered in the 8U1 feature blog here. Once configured, this will automatically create the relevant SPBM policy for the cluster.

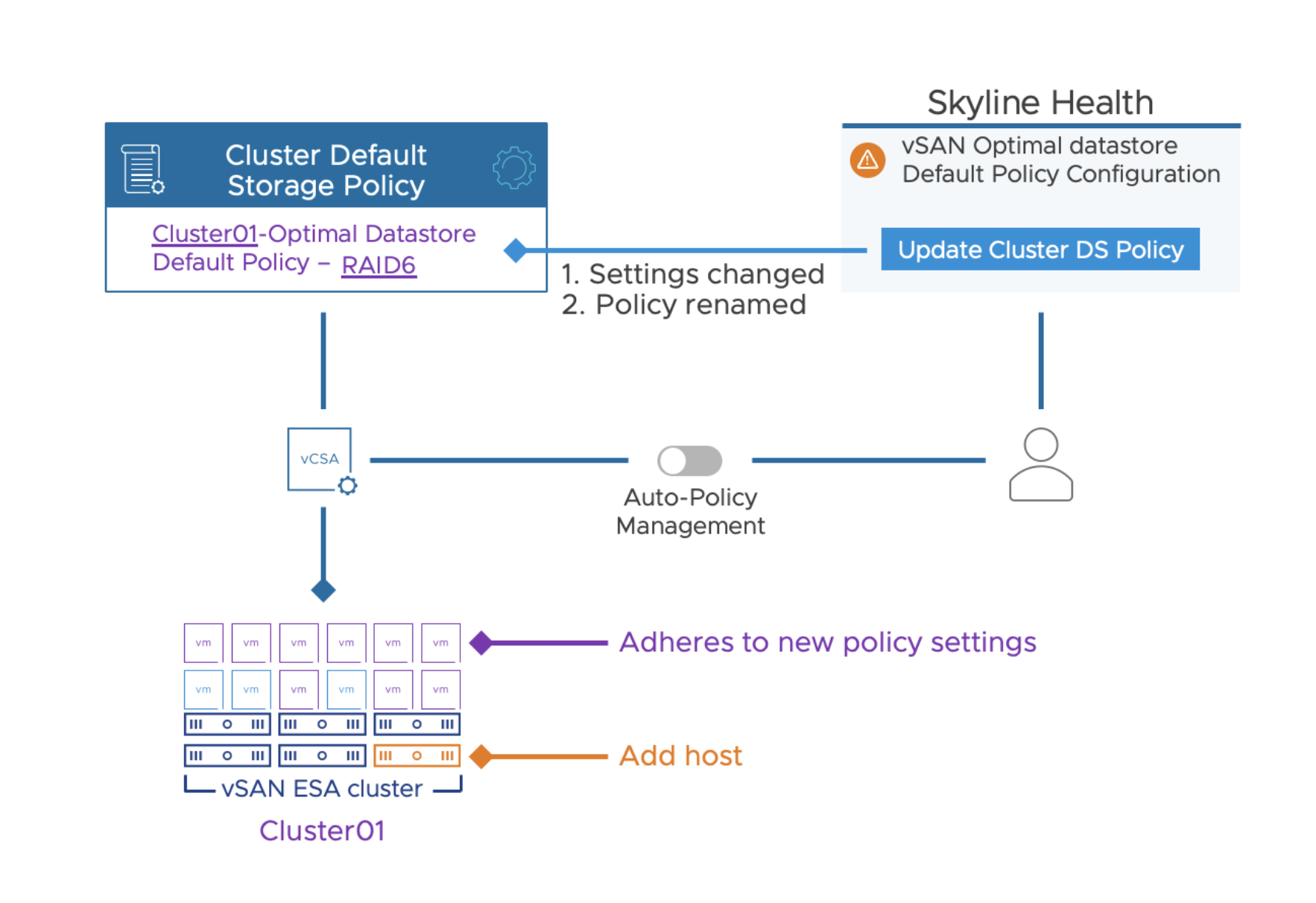
Upon the addition or removal of a host from a cluster, the Auto-Policy Management feature will evaluate if the optimized default storage policy needs to be adjusted. If vSAN identifies the need to change the optimized default storage policy, it does so by providing a simple button in the triggered health finding to change the affected storage policy, at which time it will reconfigure the cluster-specific default storage policy with the new optimized policy settings. It will also rename the policy to reflect the newly suggested settings. This guided approach is intuitive, and simple for administrators to know their VM storage policies are optimally configured for their cluster. This change specifically addresses improved behavior for ongoing adjustments in the cluster. Upon a change to the cluster size, Instead of creating a new policy (as it did in vSAN 8 U1), the Auto-Policy Management feature will change the existing, cluster specific storage policy.
Upon a reconfiguration of the Auto-Policy generated storage policy, the automatically generated name will also be adjusted. For example, in a 5-host standard vSAN cluster without host rebuild reserve enabled, the auto-policy management feature will create a RAID-5 storage policy, and use the name of: “cluster-name – Optimal Datastore Default Policy – RAID5”
If an additional host is added to the cluster, after a 24 hour period, the following events will occur:
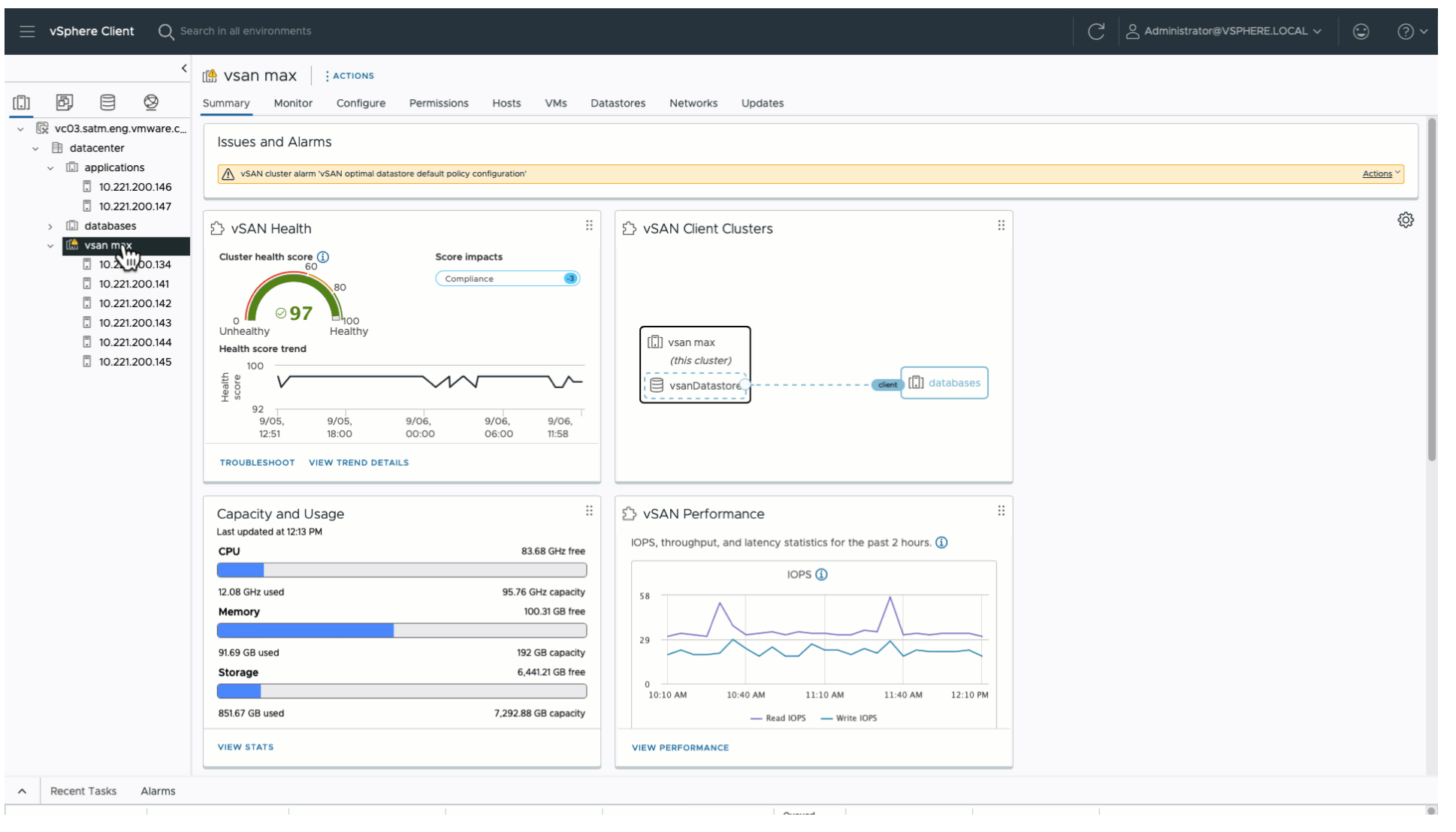
The Administrator will be prompted with an optional button “Update Cluster DS Policy.”
This will trigger two events The existing policy is changed to RAID-6 The existing policy’s name is changed to “cluster-name – Optimal Datastore Default Policy – RAID6”
As described in the steps above, vSAN 8 U2 still does not automatically change the policy without their knowledge. The difference with vSAN 8 U2 is that upon a change of a host count in a cluster, we not only suggest the change, but upon an administrator manually click on the button “Update Cluster DS Policy” we will make this adjustment for them. A host in maintenance mode does not impact this health finding. The number of hosts in a cluster are defined by those that have been joined in the cluster
Configuration Logic for Optimized Storage Policy for Cluster
The policy settings the optimized storage policy uses are based on the type of cluster, the number of hosts in a cluster, and if the Host Rebuild Reserve (HRR) capacity management feature is enabled on the cluster. A change to any one of the three will result in vSAN making a suggested adjustment to the cluster-specific, optimized storage policy. Note that the Auto-Policy Management feature is currently not supported when using the vSAN Fault Domains feature.
Standard vSAN clusters (with Host Rebuild Reserve turned off):
- 3 hosts without HRR : FTT=1 using RAID-1
- 4 hosts without HRR: FTT=1 using RAID-5 (2+1)
- 5 hosts without HRR: FTT=1 using RAID-5 (2+1)
- 6 or more hosts without HRR: FTT=2 using RAID-6 (4+2)
Standard vSAN clusters (with Host Rebuild Reserve enabled) - 3 hosts with HRR: (HRR not supported with 3 hosts)
- 4 hosts with HRR: FTT=1 using RAID-1
- 5 hosts with HRR: FTT=1 using RAID-5 (2+1)
- 6 hosts with HRR: FTT=1 using RAID-5 (4+1)
- 7 or more hosts with HRR: FTT=2 using RAID-6 (4+2)
vSAN Stretched clusters
- 3 data hosts at each site: Site level mirroring with FTT=1 using RAID-1 mirroring for a secondary level of resilience
- 4 hosts at each site: Site level mirroring with FTT=1 using RAID-5 (2+1) for secondary level of resilience.
- 5 hosts at each site: Site level mirroring with FTT=1 using RAID-5 (2+1) for secondary level of resilience.
- 6 or more hosts at each site: Site level mirroring with FTT=2 using RAID-6 (4+2) for a secondary level of resilience.
vSAN 2-Node clusters:
2 data hosts: Host level mirroring using RAID-1
Summary
The new improved Auto-Policy Management feature in vSAN 8 U2 serves as a building block to make vSAN ESA clusters even more intelligent, and easier to use. It gives our customers confidence that resilience settings for their environment are optimally configured.