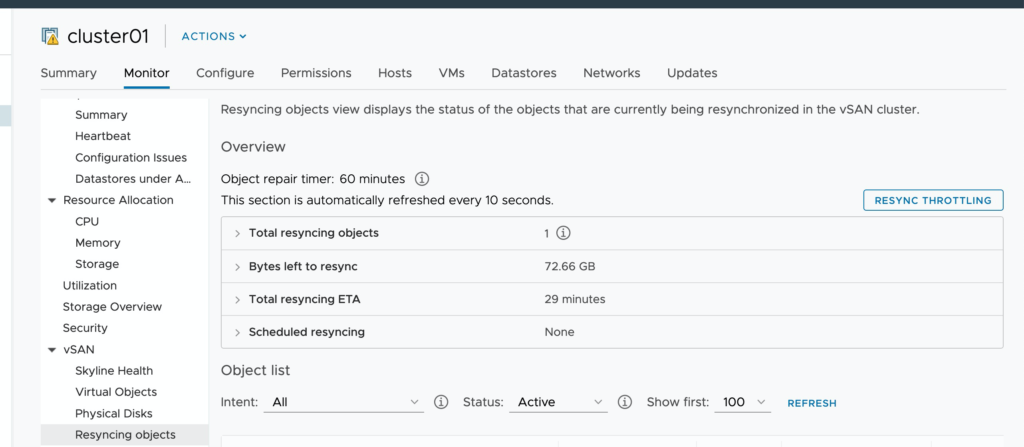
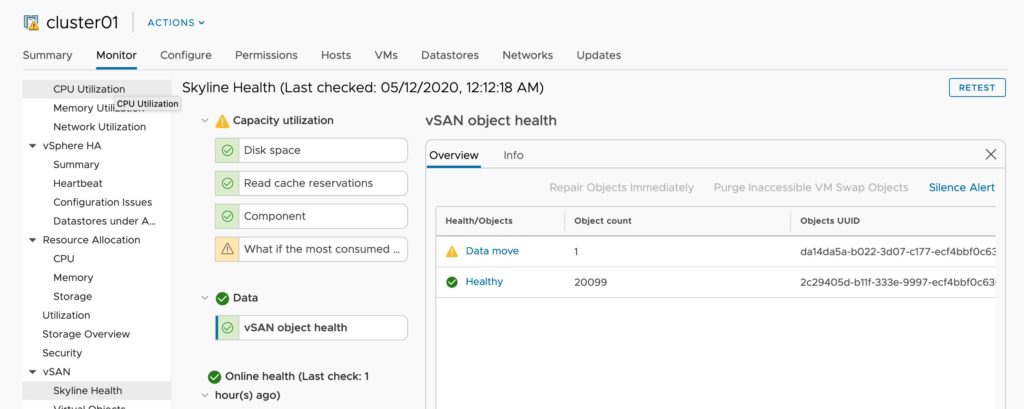
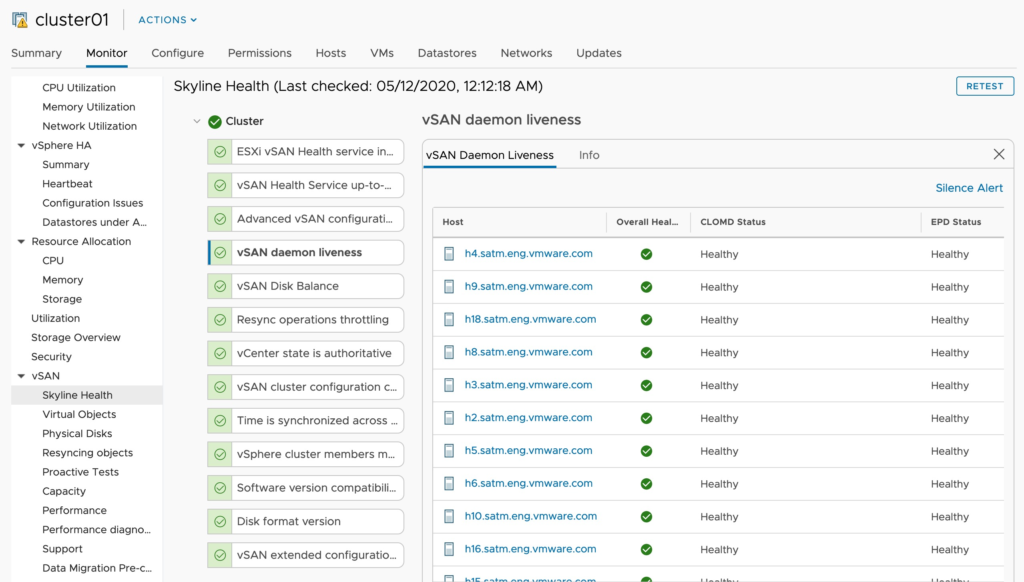
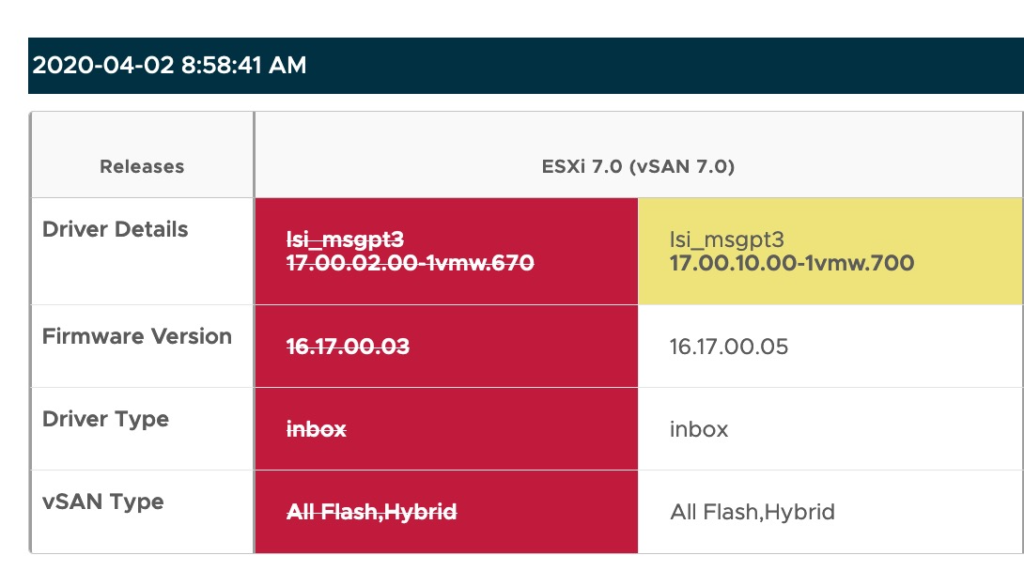
So as i complete this series I wanted to include some screenshots, examples of the order of operations I used, and discuss some of the options or ways to make this faster.
Disclaimer: I didn’t end to end script this. I didn’t even leverage host profiles. This is an incredibly low automation rebuild (partly on purpose, as we were training someone relatively new to work with bare-metal servers as part of this project so they would understand things that we often automate). If using a standard switch (In which case SHAME use the vDS!) document what the port groups and VLANs for them are. Also, check the hosts for advanced settings.
First step Documentation
So before you rebuild hosts, make sure you document what the state was beforehand. RVtools is a pretty handy tool for capturing some of this if the previous regime in charge didn’t believe in documentation. Go swing by Robware.net and grab a copy and export a XLS of your vCenter so you can find what that vmk2 IP address was before, and what port group it went on (Note it doesn’t seem to capture opaque port groups).
Put the host into maintenance mode
Now, this sounds simple, but before we do this let’s understand what’s going on in the cluster and the UI gives us quite a few clues!

The banner at the top warns me that another host is already in maintenance mode. Checking on slack, I can see that Teodora and Myles who are several time zones ahead of me have patched a few hosts already. This warning is handy for operational awareness when multiple people manage a cluster!
Next up, I’m going to check on the Go To Pre-Check. I want to see if taking an additional host offline is going to have a significant negative impact (This is a fairly large cluster, this would not be advised on a 4 host cluster where 2 hosts would mean 50% of capacity offline, and an inability to re-protect to full FTT level).

I’m using Ensure Accessibility (The handful of critical VM’s are all running at FTT=2), and I can see I”m not going to be touching a high water mark by putting this host into maintenance mode. If I had more time and aggressively strict SLAs I could simulate a full evacuation. (Again,This is a lab). here’s an image of what this looks like when you are a bit closer to 70%.

Now, after pressing enter maintenance mode I’m going to watch as DRS (which is enabled) automatically evacuates the virtual machines from this host. While a rather quick process I’m going to stop and daydream of what 100Gbps Ethernet would be like here and think back to the stone ages of 1Gbps ethernet where vMotions of large VMs was like watching paint dry…
Once the host is in Maintenance Mode I’m going to remove this host from the NSX-T Manager. If your not familiar with NSX-T this can be found under System → Fabric → Nodes and THEN use the drop down to select your vCenter (it defaults to stand alone ESXi hosts).
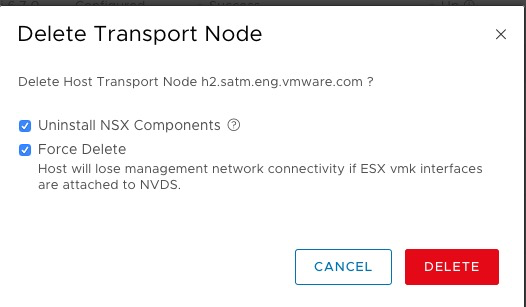
Once the host is no longer in NSX-T, and out of maintenance mode you can go ahead and reboot the host.
Working out of band
As I don’t feel like flying to Washington State to do this rebuild, I’m going to be using my out of band tooling for this project. For Dell hosts this means iDRAC, for HPE hosts this means iLO. When buying servers always make sure these products are licensed to a level that allows full remote KVM, and for Dell and HPE hosts you have the additional licensing required for vLCM. (OMIVV and HPE iLO Amplify). Some odd quirks I’ve noticed is that while I personally hate Java Web start (JWS) as a technology, the JWS console has some nice functionality that the HTML5 does not. Being able to select what the next boot option should be, means I don’t have to pay quite as much attention, however the JWS is missing an on screen keybaord option so I did need to open this from the OS level to pass through some F11 commands.

while I’m at it, I’ll go ahead and mount the Virtual Media, and attach my ESXi ISO to the Virtual CDROM drive.
Firmware and BIOS patching
Now if you are not using vLCM it might be worth doing some firmware/bios update at this time. for Dell hosts, this can be done directly from the iDRAC by pointing them at the downloads.dell.com mirror or loading an ISO.

BIOS and boot configuration
For whatever reason, my lab seems to have a high number of memory errors. To help protect against this I’m switching hosts by default to run in Advanced ECC mode. For 2 hosts that have had chronic DIMM issues that I haven’t had time to troubleshoot I’m taking a more aggressive stance and enabling fault resilient mode. This forces the Hypervisor and some core kernel processes to be mirrored between DIMMs so ESXi itself can survive the complete and total failure of a memory DIMM (vs Advanced ECC which will tolerate the loss of subunits within the DIMM). For more information on memory than you ever wanted to know, check out this blog.


Next up I noticed our servers were still set to a legacy boot. I’m not going to write an essay on why UEFI is superior for security and booting, but in my case I needed to update it, if I was going to use our newer iPXE infrastructure.

Note upon fixing this I was greeted by some slightly more modern versions.
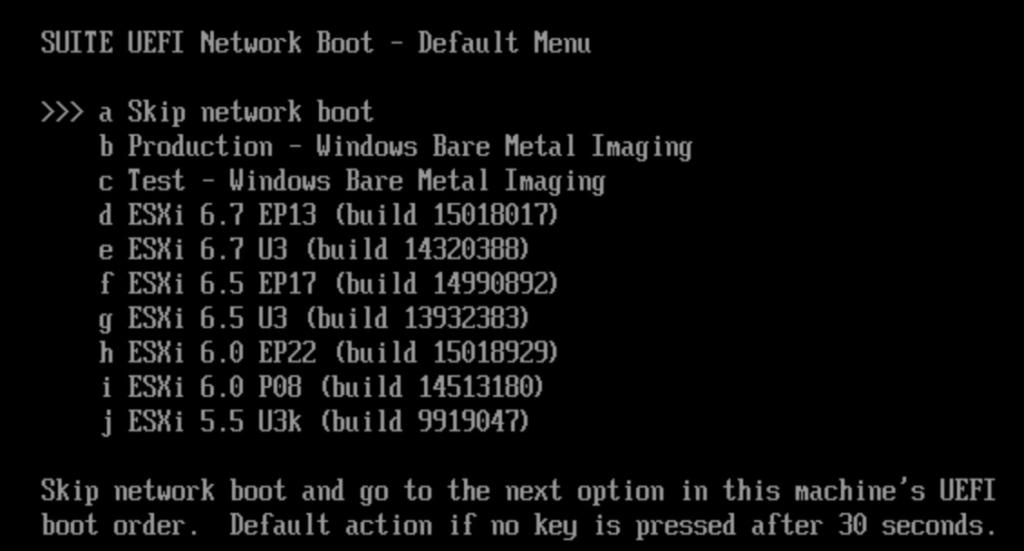
Now, if you don’t have a fancy iPXE setup you can always mount the ISO to the virtual CDROM drive.
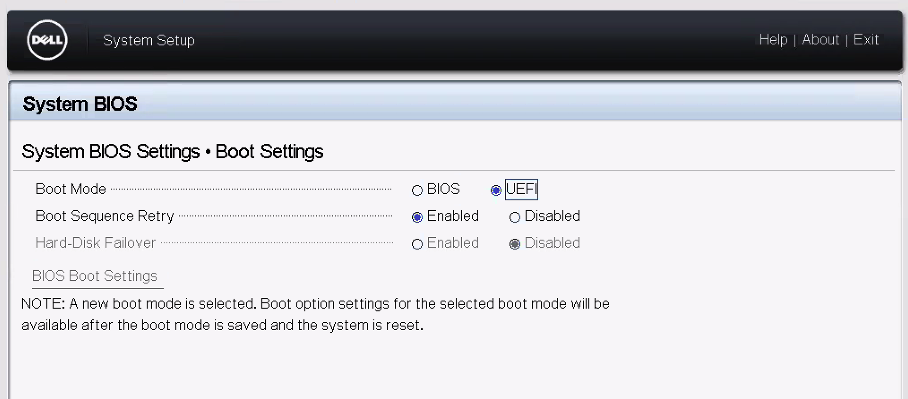
Note: after changing this you will need to go through a full boot cycle before you can reset the default boot devices within the BIOS boot manager.
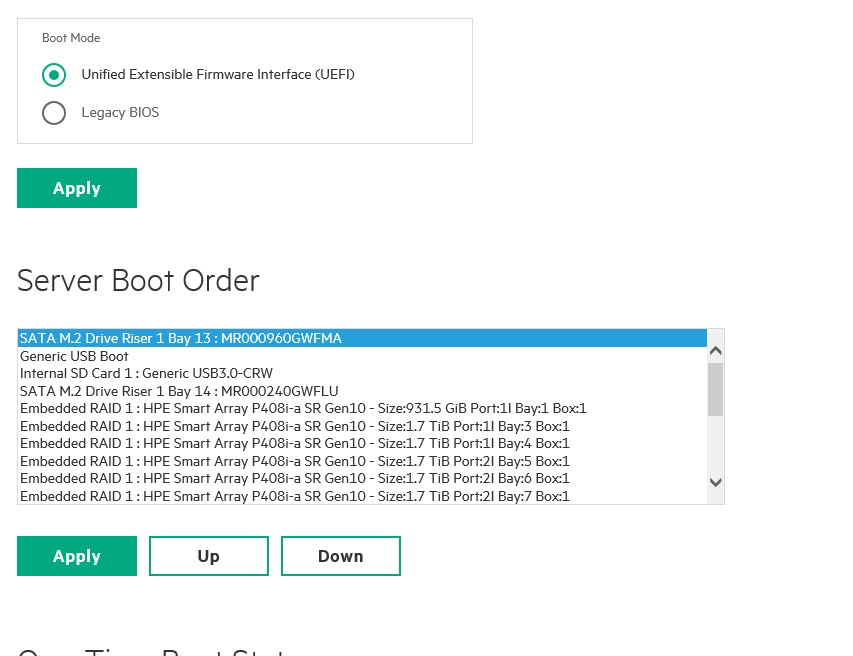
Now I didn’t take a screenshot on my Dell of this, but here’s one of the HPE hosts, what it looks like to change the boot order. The key thing here is to make sure the new boot device is first in this list (As we will be using one-time boot selection to start the installer).
Coffee Break
Around this time is a great time for some extra coffee. Some things to check on.
- Make sure your ISO is attached (Or if using PXE/iPXE the TFTP directory has the image you want!).
- make sure the next boot is set to your installer method (Virtual CD Room, or PXE).
- Go back into NSX-T manager and make sure it doesn’t think this host is still provisioned or showing errors. If it’s still there unselect “uninstall” and select “Force delete”. This tends to work.
- Collect your notes for the rest of the installation NTP servers, DNS servers, DNS suffix/lookup domains, IP and hostname for each host (If your management domain has DNS consider setting reservations for the MAC address of VMK0 which always steals from the first physical NIC so it will be consistent, unlike the other ones that generate from the VMware MAC range.)
- Go into vCenter and click “remove from inventory” on the disconnected host. We can’t add a host back in with the same hostname (This will make vCenter angry).