What to look at and do (or not) when recovering from a cluster failure (Part 2)

In part one of this series, I highlighted a scenario where we lost quite a few hosts in a lab vSAN cluster caused by 3 failed boot devices and a power event that forced a reboot of the hosts. Before I get back into the step by step of the recovery I wanted to talk a bit about what we didn’t do.
What should you do?
- If this is production please call GSS. They have unusually calm voices and can help validate decisions quickly and safely before you make them. They also have access to recovery tooling, and escalation engineers you do not have.
- Try to get core services online first (DNS/NTP/vCenter). This makes restoring other services easier. In our case, we were lucky and had only partial service interruption here (1 of 2 DNS servers were impacted).
Cluster Health Checks
While, I much prefer to work in vCenter, in the event of vCenter having an outage, it is worth noting that vSAN health checks can be run without vCenter.
- Run at the CLI
- Run from the Native HTML5 client on each ESXi host. The cluster health is a distributed service that is independent of vCenter for core checks.

When reviewing the impact on the vSAN cluster look at the Cluster Health Checks:
- How many objects are re-syncing, and what is the progress.
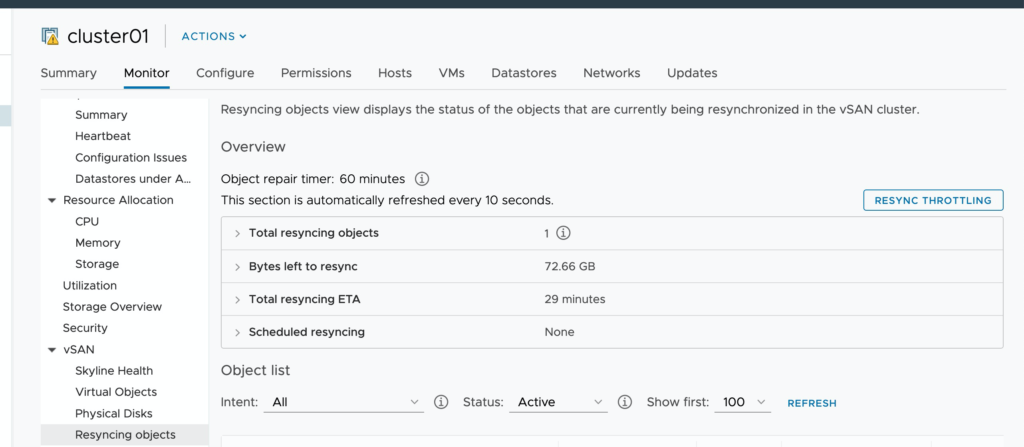
2. How many Components are healthy vs. unhealthy
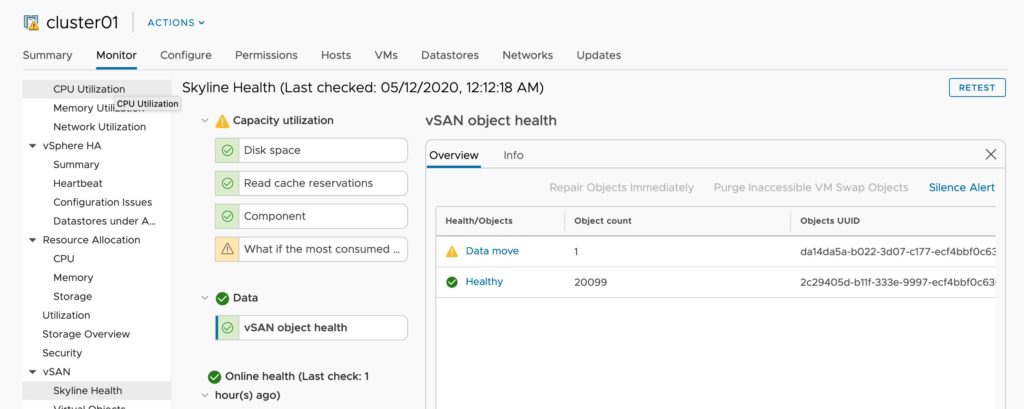
3. Drive status – How many drives and disk groups are offline. note, within the disk group monitoring you can see what virtual machine components were on the impacted disk groups.
4. Service Check. See how many hosts are reporting issues with vSAN related services. In my case this was the hint that one of my hosts had managed to partially boot, but something was wrong. Inversely if you may see a host that is showing disconnected from vCenter, but is still contributing storage. It is worth noting that vSAN can continue to run and process storage IO as long as the vSAN services start, and the vSAN network is functional. It’s partly for this reason that when you enable vSAN, the HA heartbeats move to the vSAN network, as it’s important to keep your HA fencing in line with storage.
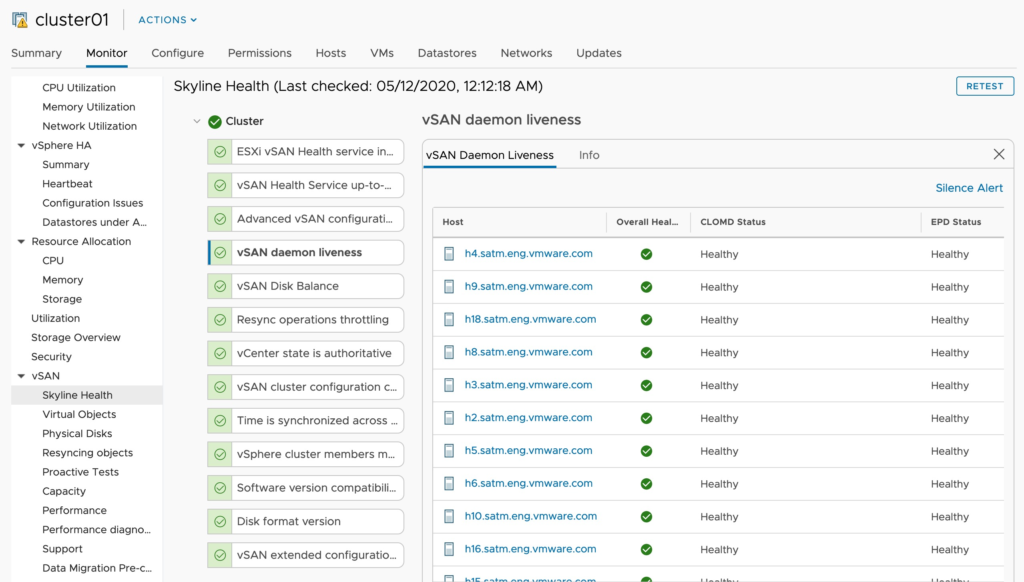
5. Time is synchronized across the cluster. For security reasons, hosts will become isolated if clocks drift too far (Similar to active directory replication breaking, Kerberos authentication not working etc. Thankfully there is a handy health check for this.

What Not to do?
Don’t panic!

Also, while you are at it, don’t reboot random hosts.
This advice isn’t even specifically vSAN advice, but unlike your training with Microsoft desktop operating systems, the solution to problems with ESXi is not always to “tactically reboot” a host by mashing reset from the iDRAC. You might end up rebooting a perfect health host that was in the middle of a resync, or HA operation. Rebooting more health hosts does a few things:
- It causes more HA events. HA events trigger boot storms. large bursts of disk IO as an Operating system reboots, databases force log rechecks, in-memory databases rebuild their memory caches and other processes that are normally staggered.
- Interrupt object rebuilds. In our case (3 hosts failures and FTT=1) we had some VM’s that we lost quorum on, but many more that only lost 1 of 3 pieces. Making sure all objects that can be repaired are repaired quickly was the first order of battle.
- Rebooting hosts can dump logs or crash dumps that are not being written to persistent disk. GSS may want to scrape some data out of even a 1/2 dead host if possible.
Assemble the brain trust

A few other decisions came up as Myles, Teodora and I spoke about what we needed to do to recover the cluster. We also ruled out a few recovery methods and decided on a course of action to get the cluster stable, and then begin the process of proactively preventing this from impacting us with other hosts.
- Salvage a boot device from a capacity device – We briefly discussed grabbing one of the capacity devices out of the dead hosts and using it as a boot device. Technically this would not be a supported configuration (or controller is not supported to act as both a boot device and a device hosting vSAN capacity devices). The challenge here is we wanted to get back 100% of our data and it would have been tedious to identify which disk group was safe to sacrifice in a host for this purpose. If we were completely unable to get remote hands to install boot devices or were only interested in the recovery of a single critical VM at all costs, this might have made sense to investigate.
- Drive Switcharo– Another option for recovery has our remote hands pull the entire disk group out of the dead servers and shove them into free drive bays on existing healthy servers. Pete Koehler mentioned this is something GSS has had success and something I’d like to dedicate to its own blog topic at some point. Why does this work? Again, vSAN does not store metadata or file system structures on the boot devices, purposely to increase survivability in cases where the entire server must be replaced. This historically was not a common behavior in enterprise storage arrays that would often put this data on OS/vault drives (that might not be movable even, or embedded). Given we had adequate drive bays free to split the 6 impacted disk groups (2 per host) across the remaining 13 hosts in the cluster this was an option. In our case, we decided we didn’t want to deal with moving them back after this was done. My remote hand’s teams were busy enough with vSphere 7 launch tasks, and COVID related precautions were reducing the staffing levels.
- Fancy boot devices – We decided to avoid trying to use SD cards going forward as our primary boot option (even mirrored). Once these impacted hosts were online and the cluster was healthy we had ops plug in all of our new boot devices so we could proactively one host at a time process a fresh install. In a perfect world we would have had M.2 boot devices, but adding a PCI-E riser for this purpose on 4-year-old lab hosts was a bit more than we wanted to spend.
What did we do?
In our case, we called our data center ops team and had them plug in some “random USB drives we have laying around” and began fresh installs to get the hosts online and restore access to all virtual machines. I ordered some high endurance Sandisk USB devices and as a backup some high endurance SD cards (Designed for 4K Dashcam video usage). Once these came in, we reinstalled ESXi to the USB devices allowing our ops teams to recover their USB devices. The fresh high-quality SD cards will be useful for staging ISOs inside the out of band, as well as serving as an emergency boot device in the event a USB device fails.
Next up in the series. A walk through of installing ESXi from bare metal, some changes we made to the hosts and I’ll answer the question of “what’s up withe snake hiding in our R&D datacenter”.

