I tweeted this out while in Prague for the Veeam Vanguard Summit, and I’m overdue on writing out my thoughts on the topic of how do I recover quickly a 40TB database virtual machine.
When talking about having different SLAs for products or services you often hear “Good, Better, best” as the segmentation of options based on budgets and requirements. When it comes to architecture deployed for recovery from backup and replication sadly I often see people instead debate between:
“bad, awful, flaming dumpster fire” as their 3 options
. Often the worst offenders end up with data being backed up directly to backup appliances. How did we get here? I’d like to explore some of the architectural challenges facing data protection today and why dedupe appliances often fail to live up to their promise.
Disk-based dedupe appliances were not inherently bad on their own. When they first hit the market they were a great drop-in replacement for Tape. They reduced the need to manually swap tapes, and for backup workflows that sent highly duplicate data over they could optimize and compact this data. They added a significant amount of computing to these appliances so they could highly optimize data ingest speed as well as provide data reduction that previously backup software tended to not handle, or not handle well. If you wanted to stuff a lot of data into a box they were pretty useful.

The challenge of Dedupe Appliances is at the cost of being “good” at holding lots of data, they tend to be fairly bad at recovering said data. When you stuffed hundreds of virtual machines into them, often people think “how am I going to get them out of this data center clown car?”

Backup vendors have long been asked to “perform magic” and deliver faster and faster restores, despite the “physics” of moving large amounts of data taking too much time. One way to “Cheat” that has become popular is to expose an NFS share as a datastore and allow a virtual machine to be “booted” from the backup repository. Veeam Instant Recovery was an early mover in this space, but other backup vendors and DRaaS solutions have adopted similar capabilities. This works great as it avoids the traditional bottlenecks of the source and target disk speeds and network and goes straight to a running VM… RIGHT? I’ll just power on the virtual machine and then storage vMotion it over later!
Bring on the Clowns
One of the challenges of trying to run a production virtual machine is it expects the same IO performance as your primary disk. 8 years ago when primary storage was 15K RPM drives, and backup appliances used 7.2K drives that were 1/3 as fast this might have been problematic, but doable especially for a single virtual machine. Today, application owners EXPECT flash-based primary storage that delivers 100K IOPS per host at low latency. Using 7.2K drives that deliver 100 IOPS each, at 30ms+ of latency is well… A clown show. Trying to run a database virtual machine off of this storage is a bit like trying to jump-start a 737 airplane using a motorcycle engine.
How do we solve this problem?
There are quite a few approaches I’ve seen to try dig out of this hole once people realize this is not going to work:
- Identify that the vendors never promised it would work or often had limited promises (Some vendors often will support a low single digit number of virtual machines).
- Move to a 2 stage backup system, where backups land on a all flash DAS system initially and then copy out to the appliance for long term retention. (Similar to Disk to Disk to Tape workflows of old). This allows you to keep using the appliance, but just use it for what it best used for. Tiering this data out to an object storage bucket is increasing the “right choice” vs trying to have an all in one appliance.
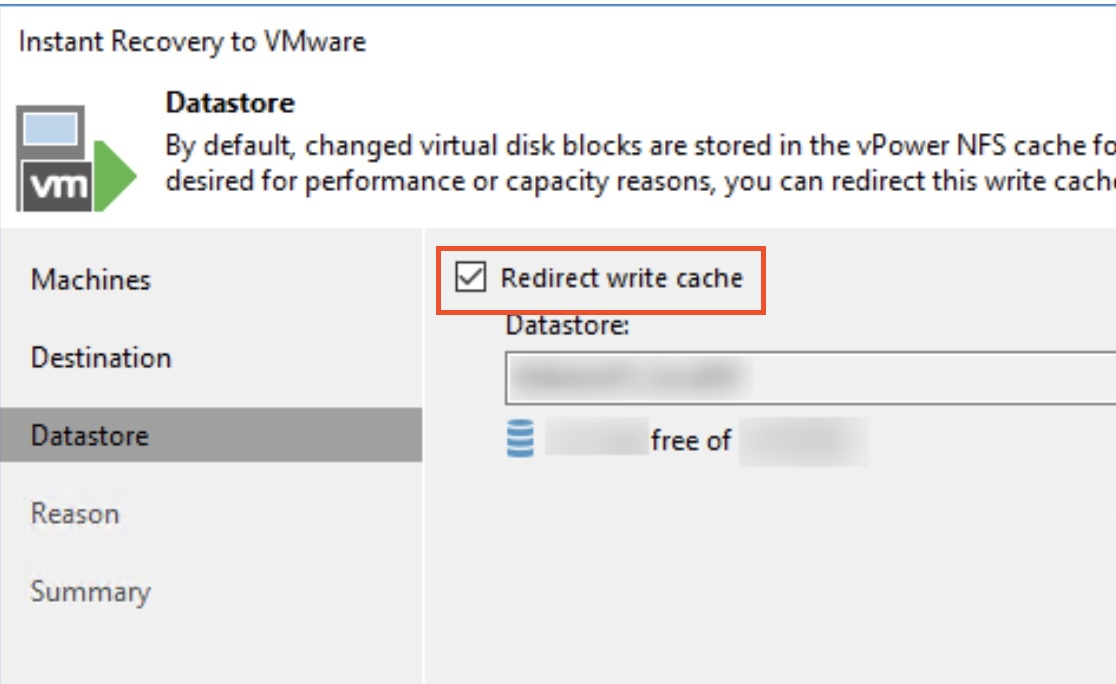
- Use caching to solve or partially mitigate this (Veeam can redirect writes, but even with this option a read heavy database on a slow dedupe target will suffer).
- Look at All Flash dedupe appliances or ones with large flash caches (Personally I’m not sold on this idea vs. just depoying a set of DL380/Apollo servers full of flash as the primary landing zone).
Disaster Recovery to the rescue.
I’ve had chats with a few customers lately who’ve recognized that for large-scale recovery of anything important, the backup repository speed is unsalvagable. Instead they “punt” and move to split out those critical recovery workflows to be powered from Replica’s that sit on a primary storage solution somewhere else. They may choose a second data center, but increasingly a DRaaS option is often making more sense, as maintaining a data center that sits idle often is not worth the effort. The other benefit of shifting to DRaaS is it often can be tied to immutable retention and provide additional ransomware recovery capabilities.