It’s come to my attention that a lot of people shopping storage really don’t know what to expect for NVMe server drives. Also looking at some quotes recently I can say some of you are getting great prices, and some of you are getting…. Well a quote…
I’m seeing discounted prices in the 12 cents (Read Intensive, Datacenter Class drives) to closer to 30 cents (Mixed use, fancier Enterprsie class drives) depending on volume and order. I’m also seeing some outliers (OEMs charging 60 cents per GB?!?!). Seeing better/worse pricing? message me on twitter @Lost_Signal.
I did look around the ecosystem and see one seller closing in on 10 cents per GB for one of the Samsung drives in an OEM caddy.
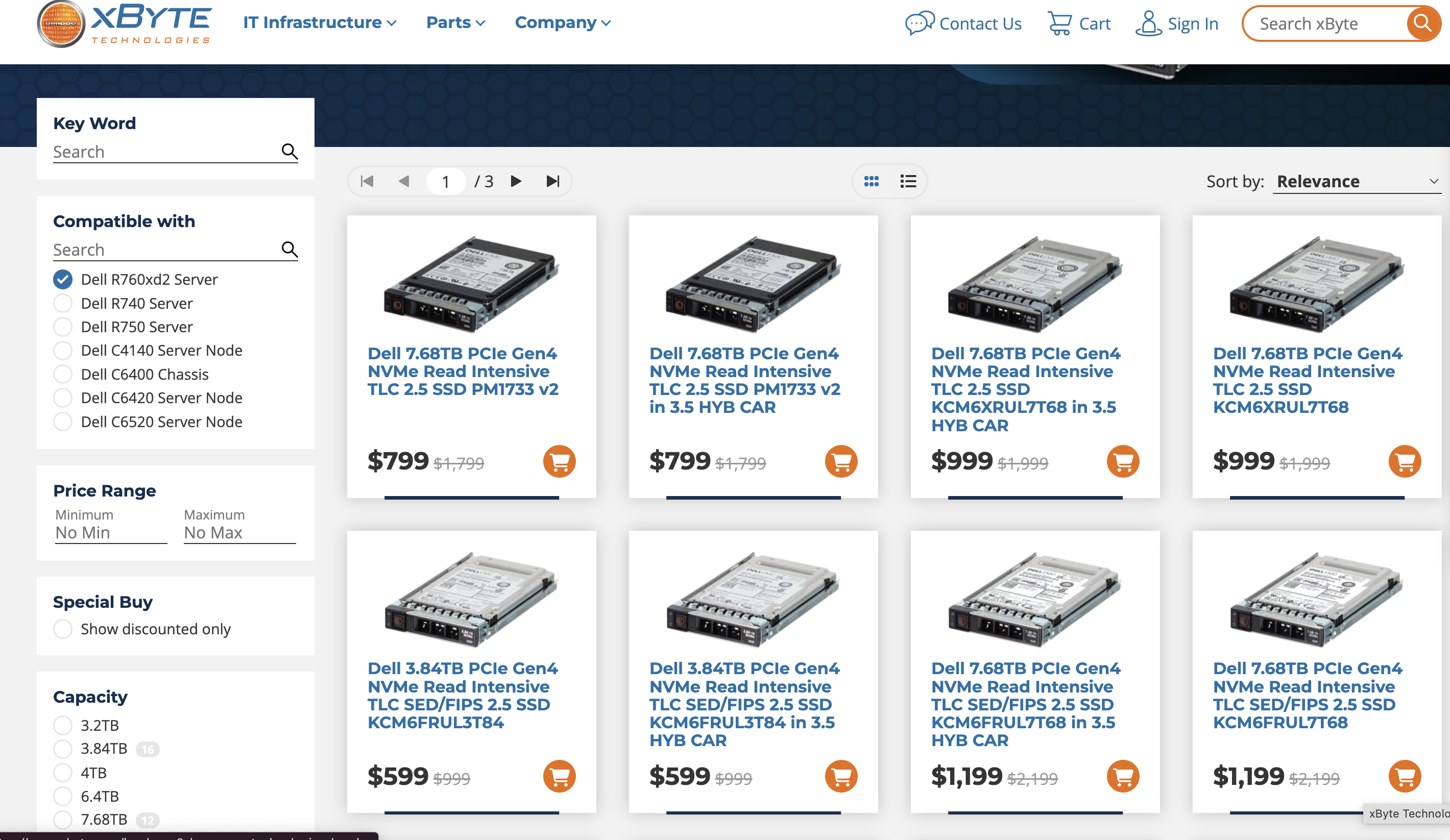
While DRAM and other component costs matter, vSAN Storage only clusters with dense nodes (200-300TiBs of NVMe) will typically see over 80% of the hardware BOM be the NVMe drives. This is driving a lot of focus on drive pricing and some awkward questions with server sales/accounting teams trying to explain charging 4-5x the going rate for drives.
So why is there such a difference in drive prices?
Drive Types
First off there’s a number of critera that can influence the price of a drive:
- What’s the endurance? Mixed-Use (3 drive write per day) drives are what vSAN ESA started with, but it is worth noting they cost more. How much more? ~20% more than Read Intensive drives that only support 1 DWPD. Do I need Mixed use? In short most of you do not, but you should check your change rate, or write rate. Very high throughput data warehouses doing tons of ETLs or large automation farms may see the need to pay the fancier drive that will last longer, and likely have better high end write throughput. I would expect 90% of clusters can use Read Intensive drives though at this point.
- Enterprise or Datacenter class TLC drives – Much like “value SAS” before a cheaper slightly less featured (single port vs. 2 port which does NOT matter inside a server), slightly less performant class of NVMe drive is showing up on quotes. I’m so far a fan, for anything but ultra high write throughput workloads it should save you some money. It’s positioned well to replace SATA. and furthers the argument that vSAN OSA is a legacy platform, and ESA should be all new builds. Speaking to one vendor recently they were skeptical of the need for QLC NAND when the cheaper “Datacenter class” TLC can hit pretty solid price points without some of the performance and endurance limits that QLC currently faces (To be fair, we all said the same thing about SLC, and MLC and TLC before, so in the long run I”m sure we will end up on QLC and PLC eventually).
- SAS/SATA are not supported by vSAN ESA, but frankly I’m seeing prices at the same or frankly worse for similarish SAS drives. I don’t expect SAS/SATA to show up in the datacenter much going forward beyond maybe M.2 boot devices.
Price List and Discounting
- Price list price. Note there are two factors at play here. A vendor will have a list price that is HIGHLY inflated (think 10-12x the component cost to them or even a normal person purchasing that device). These price lists are not consistent vendor to vendor. Price lists are not always universal, they might be per country, by quarter, by contract vehicle and by company. Negotiated price lists can do some weird things. vehicles that are not updated quarterly effectively mean you have committed to worse prices over time (As market prices go down). Also older price lists will not include newer drives or SKUs that are cheaper, sometimes forcing customers to purchase older servers/drives etc at higher cost.
- Discount % – When I ask people what they pay for drives or servers they often reply with a discount percent, with a slight bit of excitement and zero context. This is a bit like me telling people I paid 30% off for an air filter yesterday. (30% of WHAT?) Discussing discount without knowing the price list markup is a bit like buying a car without knowing what currency you are negotiating in. Different OEMs have different blends of markup, and base discounts. One Tier 1 vendor OEM’s example of expected discounts are:
55% – Anyone with a pulse should get this discount.
65% – If you found a partner and they felt like making 20% off of you, this is your normal pricing for a small order from a small company.
75% – A reasonable normal discount
85% – A large order, or an order from a large company who does a lot of purchasing.
90%+ You bought a railcar sized order.
Some factors that can influence discount size:
Note Tier 2/3 OEMs tend to have much more “Street ready pricing” by default.
Some factors that can influence discount size
- Size of deal – Larger orders can discount more.
- Financial Shenanigans – Some server vendors are currently trying to operate as a SaaS companies in their financial reporting to wallstreet. As part of this cosplaying as a subscription service, they will only quote sane discounts/prices if you structure the deal as a subscription deal. They may require this have a cloud connected component that in reality has no real value, but I assure you is required by auditors to comply with ASC 606 accounting regulations
and totally isn’t dubiously stretching the line at the unique value requirements of the cloud bits. If you do not want a quote that costs 3x what it should, and would like servers delivered this year instead of 2026, I suggest you roll your eyes, and ask for that new cloud thing!. - Competitive pressure – Competitive deals (meaning there is another vendor quoting servers or drives) typically unlocks 10-30% better pricing for the sales team. If you NEVER quote anyone else (even as a benchmark) you will discover your pricing power even at scale slowly atrophies over time. Seriously, go invite Lenovo, or Hitachi, Fujitsu or some other vendor to throw a quote at the wall. Even if you likely plan to stick with your existing OEM, you will find this helps keep pricing a bit more honest.
Vendor doesn’t want to sell you the drives (because they want to sell something else!)– This one is weird, but if you are asking a VAR/Server vendor who also sells storage to quote you NVMe drives for vSAN… They may have a perverse incentive to mis-price them so they can sell you a higher margin external storage array. Server components (especially to partners, I used to work for one!) tend to offer less margin, and vendor sales reps may have quota buckets they need to fill in storage. This reminds me of the wise words of Eric.
Common factors for higher prices
“The customer gets ONE of the votes on what they get to buy” – Enterprise Storage sales rep who I saw make 700K in commission.
You specified a very specific drive they don’t have in stock – Vendors have gotten increasingly annoyed with being forced to stock like for like parts for replacement, and supply chain management of 40 different NVMe drive SKUs (performance, encryption, endurance, capacity variables) has allowed their supply chain guys to offer discounts for “Agnostic SKUs” (where you get something that meets the spec). While I am partial to some specific drive SKUs this can cost you anywhere from 20% to 100% as well as delays in shipping. By discounting drives they have to sell and want to sell they can make sure the server gets sold in THIS quarter so they can book revenue now.
Sandbagging, SPIFFS and other odd sales behaviors – People who sell most of the time want to help the customer solve a problem. That said they also are driven by a long list of various incentives to sell specific things at specific times. This is referred to as “Coin-Operated” behavior. Sandbagging is a term used when a sales team purposely slows down a deal. This could be because they have hit a ceiling on how much commission they can earn, or accelerators to their commission. SPIFFs are one off payments for selling specific things, often paid not by the sales teams employer but a manufacturer or partner directly. It frankly always felt strange to have a storage vendor trying to pay me in Visa Gift cards on the side (I generally refused these, as it felt like a illicit transaction) but it does happen.
#vSAN #ESA #NVMe #TCO #Price