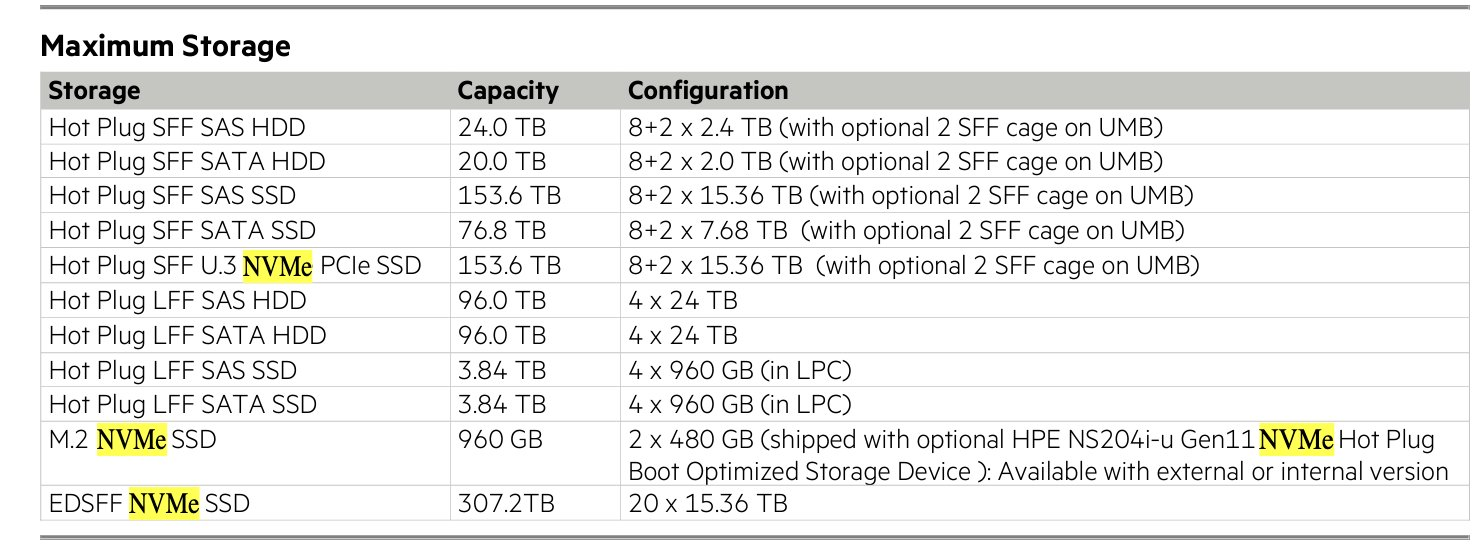
New in vSAN 9.1 are two key space saving technologies:
- General availability of global deduplication
- It now supports operation with encrypted clusters
- A new compression family is in use that achieves much better compression. This builds on advancements in ESA compression over OSA compression (block granularity is much smaller).
vSAN Compression 9.1
The compression process is “in-line”. This means it happens “in the I/O path” on all inbound writes. While in theory this costs some CPU to perform, it reduces CPU in other ways (reduces the amount of TCP overhead to push packets over the storage network, reduces the data that has to be committed to disk etc). The savings helps offset the cost of compression. As a result of the trade-offs and benefits here in compute overhead compression is now ALWAYS ON in 9.1. If you write data it’s compressed and then sits on disk and is “done”…. or is it…
Deduplication I/O path
Deduplication is instead an optional feature, and it operates post-process. This means it is NOT in the write I/O path. I get asked a lot
“How much compute should I plan for deduplication to need with vSAN ESA”
“What is the performance impact on writes for deduplication.”
These are valid concerns, as inline deduplication can be quite CPU thirsty, as well as it also tends to potentially bottleneck write throughput (or require other compromises, or cost overheads like dedicated accelerators).
By operating as a post process system, vSAN ESA deduplication can dynamically run when there is free compute resources on the hosts. This means from a CPU budgeting in sizing you need to allocate 0% CPU to deduplication. Remember, free CPU cycles can not be saved in a jar for next week, and idle CPU cycles only cost small variations in power usage on an otherwise idle core. CPU is fundamentally a real time commodity, and as such we do not need to concern ourselves with it’s overheads.
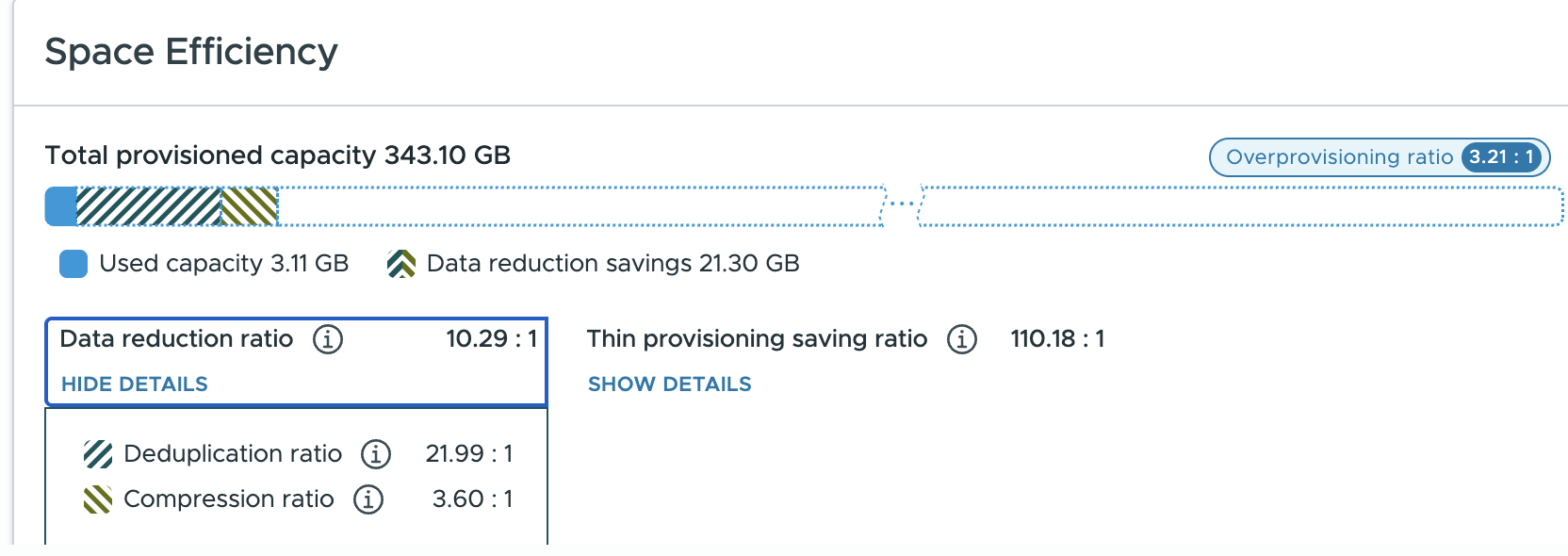
If compression is inline, “Why am I seeing the compression ratio go up and down on an otherwise idle cluster?”. Clearly, there must be a post-process occurring with compression? Yes and no…
Yes, there is a post-process (deduplication), but no, it’s not compression that is running on idle data. What you are seeing is that as deduplication runs, it will deduplicate highly compressed data (which makes the compression ratio go down) as well as deduplicate poorly compressed data (which makes the compression ratio go up).
vSAN ESA in 9.1 brings highly competitive deduplication and compression ratios to the main stage and does so while keeping CPU usage under control. This ensures that the consolidation of compute workloads can be just as efficient as storage.