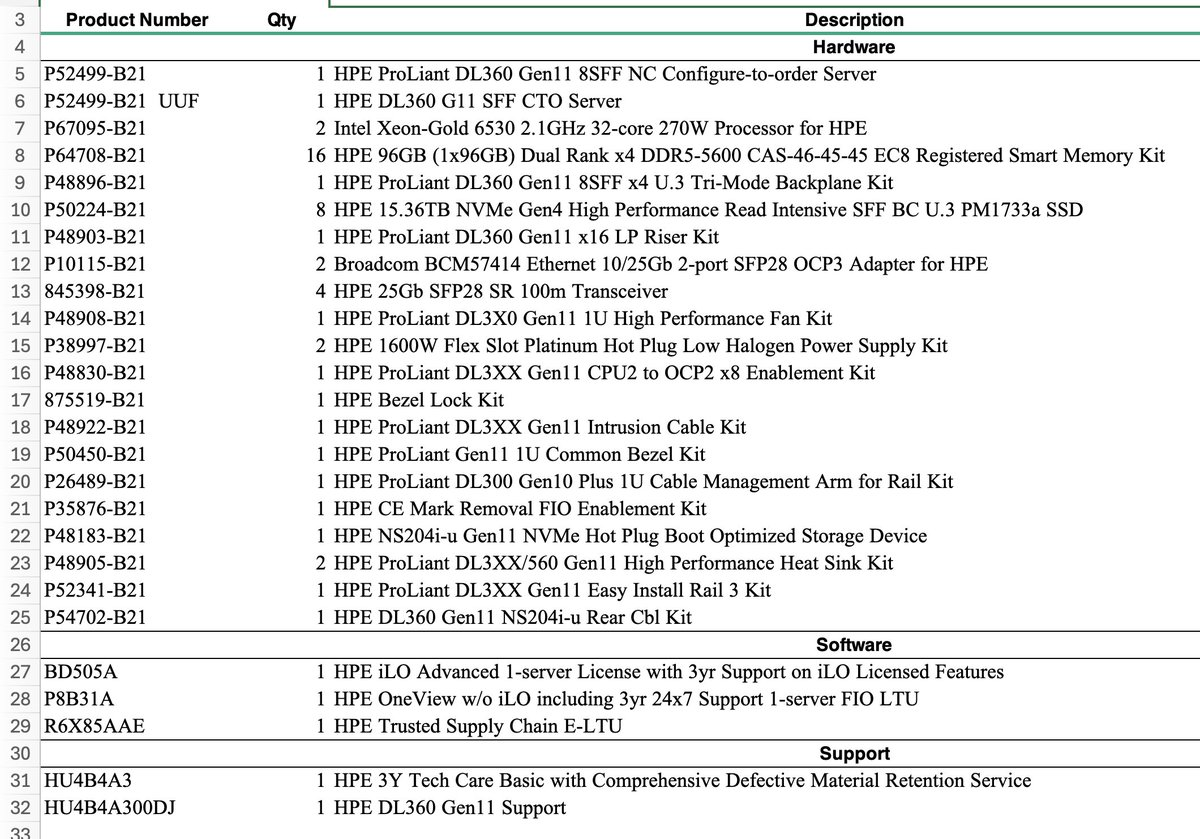
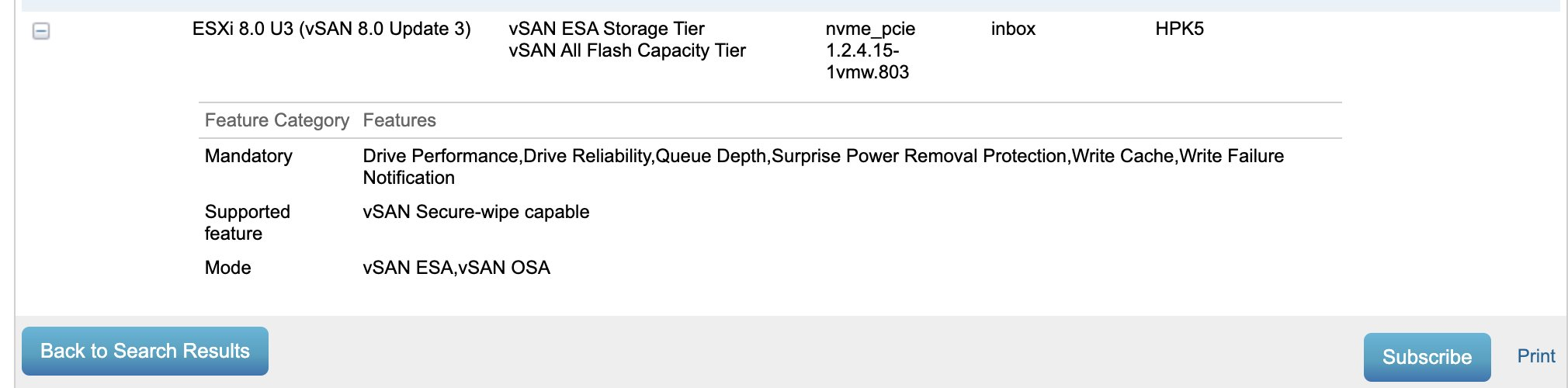
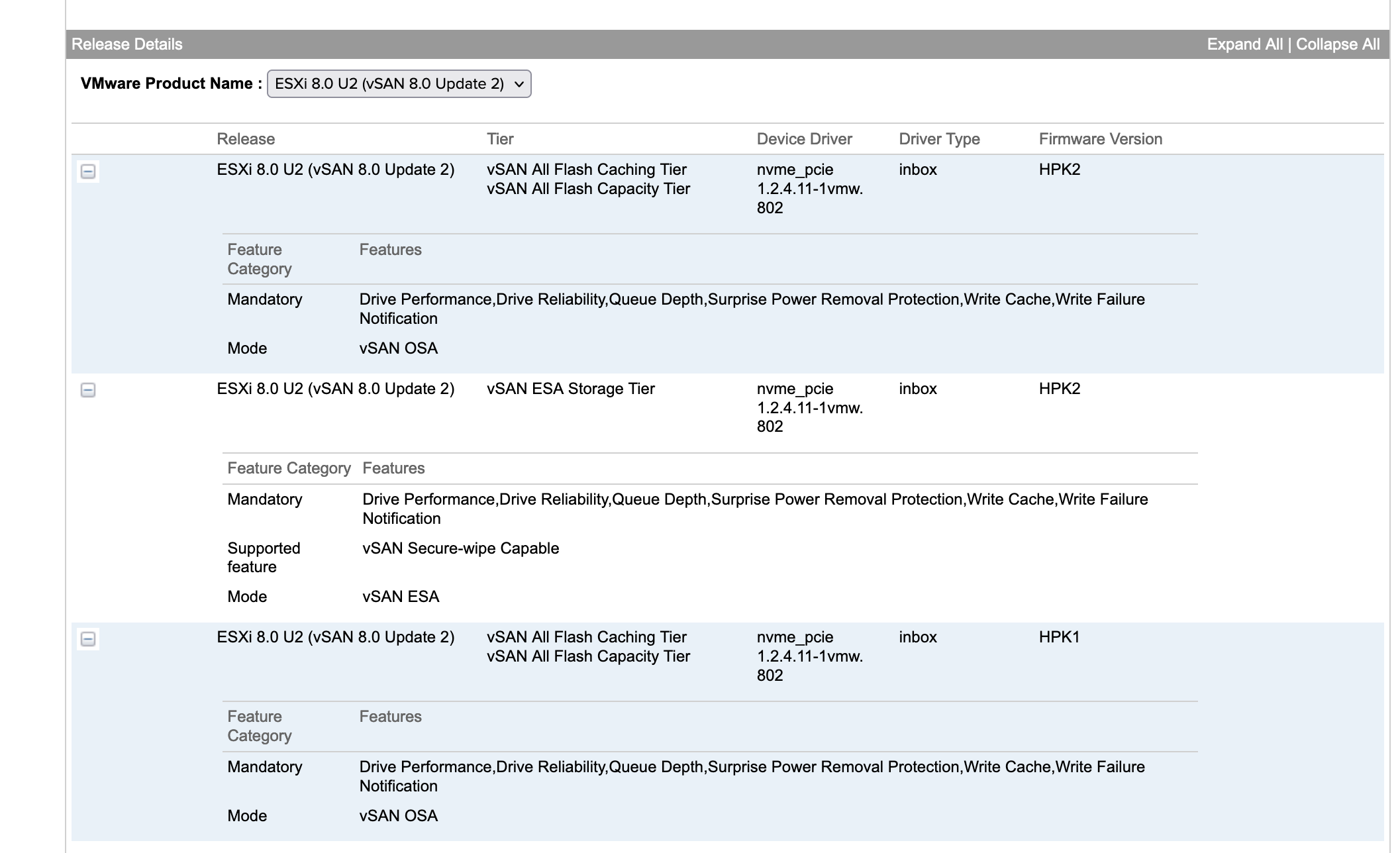
The hybrid configuration in vSAN Original Storage Architecture feature will be discontinued in a future VCF release.
Hybrid vSAN, was a great start to vSAN and continued along for a while for “lowest cost storeage” but it quickly makes less and less sense because of of a combination of software and hardware changes. Over time the place of slow NL-SAS drives in the I/O path has been pushed farther and farther away from virtual machine storage. What has changed with vSAN to make NVMe backed vSAN Express Storage Architecture the logical replacement for vSAN Original Storage Architecture Hybrid?
Software improvements of ESA vs. vSAN OSA Hybrid
The highly optimized I/O path that VSAN ESA offers, gives RAID 1 type performance with RAID 6 being used. This gives better data protection, better capacity (300x overhead for FTT=2 hybrid vs. 1.5x).
vSAN ESA offers compression and global de-duplication across the entire cluster helping compact data even data compaction.
vSAN ESA also negates any need for “cache devices” further reducing the bill of materials cost. The “bad” performance of magetic drives was blunted by use of larger cache devices but now your paying for flash that does not increase the capacity of the system.
Hardware Improvements:
vSAN ESA today supports “Read Intensive” flash drives that are 21 cents per GB. Combined with the above mentioned data efficiency gains it’s possible to have single digit “cents” per GB effective storage for a VCF customer. Yes I”m viewing software as a sunk cost here, please do your own TCO numbers, and competitively bid out multiple OEMs for flash drives!
The reality of Magnetic drives
As the industry has abandoned “Fast” 15K/10K drives, the only drives shipped in any quantity are 7.2K NL-SAS drives. These drives at best tend to perform “80-120” IOPS (In out operations per second). If you have worked with storage you may have noticed that this number has not improved in the last decade. It’s actually worse than that, as the 1TB NL-SAS drive you were looking at 12 years ago had a higher density of performance per GB than current generation.
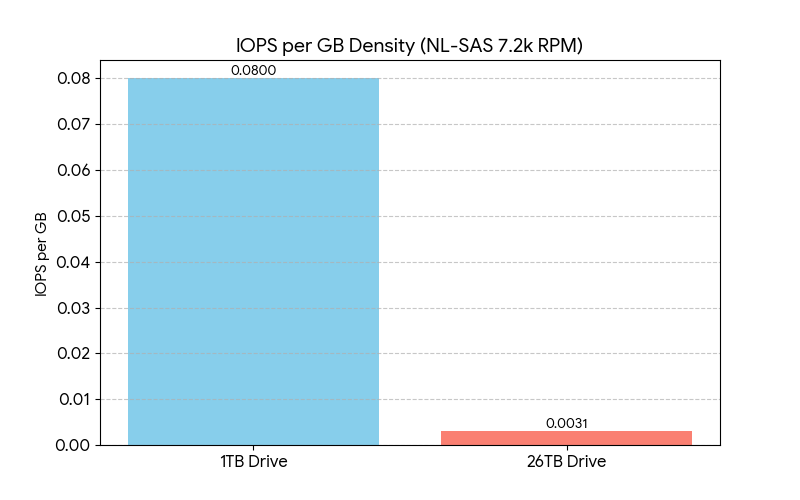
Note that 100 does’t mean sub-ms latency, it means a minimum of Queue Depth of 4-8 and Native Command Queueing re-ordering commands in the most optimal way and latency is going to be 45-80ms (Which is considered unacceptable in 2025 for transactional applications). Users are no longer willing to “Click” and wait “seconds” for responses in applications that need multiple I/O checks. It’s not uncommon to hear storage administrators refer to NL-SAS 7.2K RPM drives as “Lower latency tape.” Large NL-SAS drives (10TB+) are suitable only for archives, backups, or cold object storage where data sits idle. They are generally too slow for active workloads.
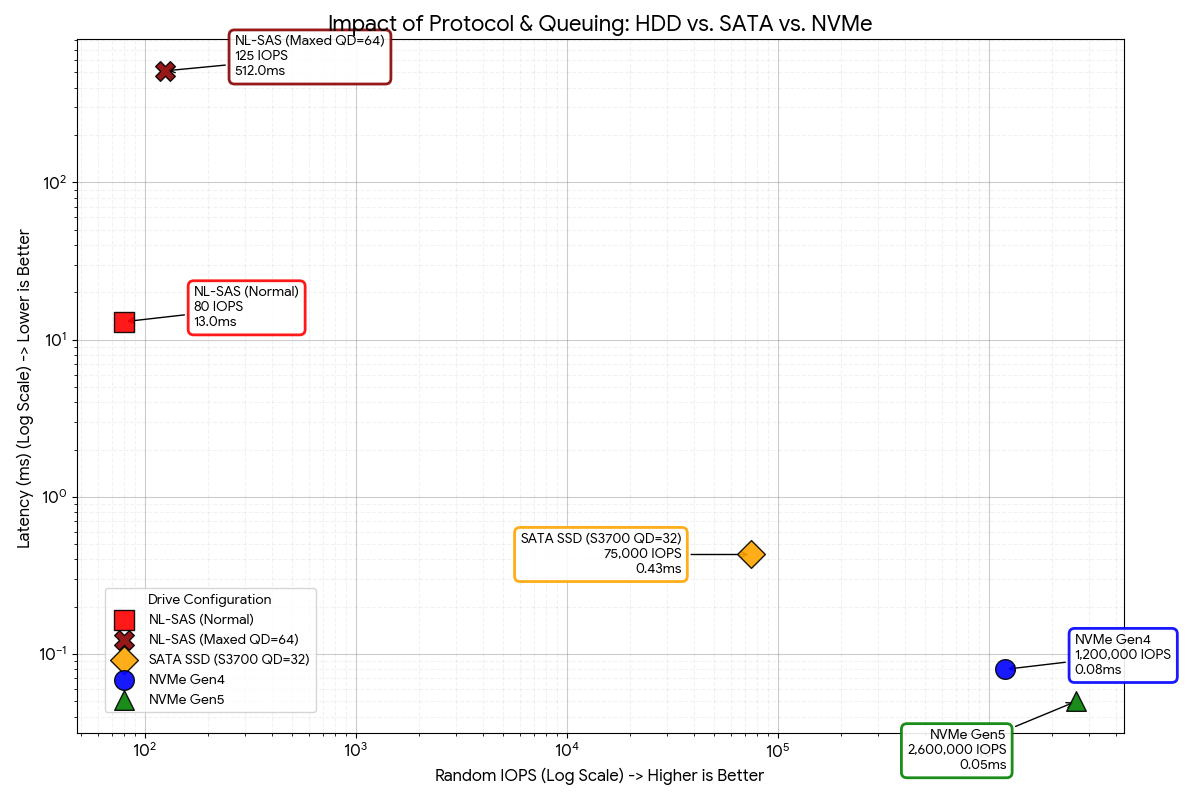
The delta in performance between between magnetic drives and the $3 per GB SATA drives when vSAN launched was large, but the jump to NVMe drives requires a logarithmic scale to measure in a meainful way that does not look ridiculous.
Single Tier ESA vs. Cache design
1. Cache Misses as capacity scaled increasingly are brutal. It’s a bit like shifting from 6th gear to 1st gear while driving 200MPH.
2. You eventually start throwing so much cache at a workload that you have to ask “Why didn’t I just tier the data there… and why don’t I just go all flash and get better capacity efficiencies”
Even the cache drives used by OSA in the early days are anemic in performance compared to modern NVMe drives Modern NVMe drives are absolute monsters, and even with data services, and distributed data protection and other overheads in the I/O path they can deliver sub ms response times and six figure IOPS per nodes.
What about low activity edge locations?
I sometimes see people ask about hybrid for small embedded edge sites, trying to chase low cost but other benefits to ESA > OSA hybrid continue.
- ESA supports nested RAID inside the hosts for added durability. A simple 2+1 RAID 5 can be used inside of a 2 node configuration that can survive the loss of a host, the witness, and a drive in the remaining host.
- The Environmental tolerance of NVMe drives (heat, vibration, lower quality air) tends to result in less operationally expensive drive replacements.
- The Bit error rate of NVMe flash drives are significantly superior to even Enterprise NL-SAS drives.
What about Backup targets?
This blog is not highlighting a new trend. Archive tier and “copies of copies” generally are the only place that NL-SAS drives end up deployed. Increasing the industry is seeing QLC chosen as a better target for “Primary backups.” Waiting 7 hours to recover a production environment from ransomware or accidental deletion. The NL-SAS backed storage makes more sense for “beyond 90 day” and “legally mandated multi-year retention” archives. Ideally a fully hydrated “replica” on a VLR replicated cluster is ideal for stuff that wants a “minutes” recovery time objective, rather than an hour or days recovery time that NL-SAS backed dedupe appliances often deliver on.
To be fair, NL-SAS drives (like tape!) are continuing to be sold in high volume. Their use case (like tape!) though has been pushed out of the way for newer, faster more cost effective solutions for production virtual machine and container workloads. If you have nostalgia for NL-SAS drives feel free to copy your offsite DSM backup target to a hyperscaler object storage bucket as that likely is where the bulk of NL-SAS drives are ending up these days. I will caution though that QLC and private cloud object storage repo’s are coming increasing for that use case.
https://techdocs.broadcom.com/us/en/vmware-cis/vcf/vcf-9-0-and-later/9-0/release-notes/vmware-cloud-foundation-90-release-notes/platform-product-support-notes/product-support-notes-vsan.html