Should you be using Eager Zero Thick on vSAN (or VMFS)?
For vSAN No.
For VMFS, maybe?, but probably not.
Ok, I’ll agree I probably owe an explanation of why.

A quick history lesson of the 3 kinds of VMDKs used on VMFS.
thin: Space is not guaranteed, it’s consumed as the disk is written to.
thick (Sometimes called Lazy Thick): Space is reserved by the blocks are initialized lazily, so VMFS has a zero’ing cost the first time a block is written
EZT or Eager Zero Thick: The entire disk is zero’d so that VMFS never needs to write metadata. This is required for shared disk use cases, as VMFS can’t coordinate metadata updates.
These virtual disk types have no meaning on vSAN. From a vSAN perspective all objects are thin (thin vs thick vs EZT makes no difference). This is similar to how NFS is always sprase, and reservations are something you can do (with NFS VAAI) but it doesn’t change the fact that it doesn’t actually write out zeros or fill the space like it did on VMFS. On VMFS this could be mitigated largely using ATS and WRITE_SAME (With further improvements in the works). I”ve always been dubious on this benefit given how many database and applications would often write out and per-allocate file systems in advance. There are likely some corner cases such as creating a ext4 file system is slower but you can generally work around that if you really care (mkfs.ext4 -E nodiscard).
Having an EZT disk won’t necessarily improve vSAN performance the same way it does for VMFS. Pre-filling zeros on VMFS had an advantage of avoiding “burn in” bottlenecks tied to metadata allocation.
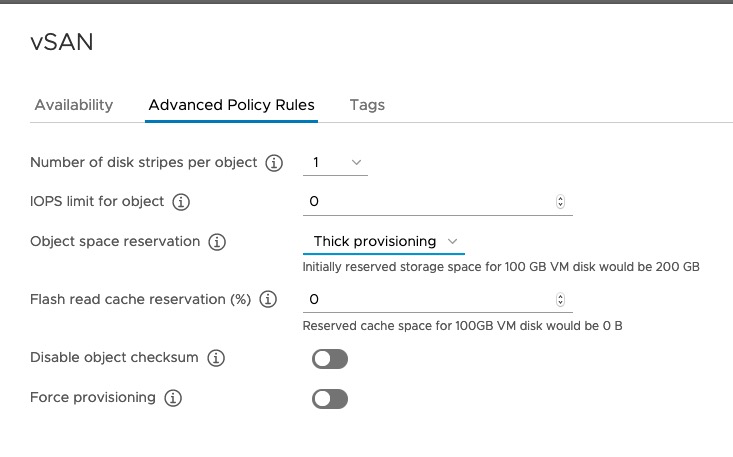
First off, vSAN has it’s own control of space reservation. the Object Space Reservation policy OSR=100% (Thick) or OSR=0% (Thin). This is used in cases where you want to reserve capacity and prevent allocations that would allow you to run out of space on the cluster. In general I recommend the default of “Thin” as it offers the most capacity flexibility and thick provisioning tends to be reserved for cases where it is impossible or incredibly difficult to ever add capacity to a cluster and you have very little active monitoring of a cluster.
What about FT and Shared Disk use cases (RAC, SQL, WFC, etc)? This requirement has been removed for vSAN. For vSAN you also do not need to configure object space reservation to thick to take advantage of these functionalities. VMFS there may still be some benefits here do to how shared VMDK metadata updates are owned by a single owner (vSAN metadata updates are distributed so not an issue).
What do I gain by using Thin VMDKs as my default?
You save a lot of space. Talking to others in the industry 20-30% capacity savings. If combined with TRIM/UNMAP automated reclaim, even more space can be crawled back! This can lead to huge savings on storage costs. As an added bonus, Deduplication and Compression work as intended only when OSR=0% and the default thin VMDK type is chosen.
Also if configured to auto-reclaim you lower the chances of an out of space condition, so this can increase availability. Eager Zero Thick or Thick VMDKs on vSAN are not going to reserve capacity in a way that prevents over commitment on vSAN, instead it will simply use more capacity.
Expect a health alarm if you have set EZT or thick VMDKs stored on a vSAN datastore. It is considered a faulty configuration. KB 66758 includes more information about this. If you need to reserve capacity (for now) use the SPBM capacity reservation policy. Additionally William Lam has a blog on this topic as well.
Have a different opinion? More questions? I’m Lost_signal on twitter.

