vSAN File Services adds a critical service to VMware Cloud Foundation. Layering a distributed protocol access layer on top of vSANs existing shared nothing distributed object store. Simplify operations and remove complexity by integrating File workloads into the infrastructure itself. For more information on how to use this with Kubernetes check out Myles Grey’s blog on the CSI integration.
I wanted to capture a few operational tasks withing vSAN File Services to show just how simple it is to setup and manage.
Setting up vSAN File Services
First off setting up vSAN is easy. You will need to setup 3-8 of the containers used for file services. each of these will need:
A unique IP address
DNS (forward and reverse)
subnet and gateway settings
In addition for the cluster you will need:
File Services Domain – This is a unique namespace for the cluster that will be used across the shares.
DNS servers – You can add multiple DNS servers for redundancy.
DNS Suffix – Note you can add multiple of these also.
https://youtu.be/poJ2ArGmHEg
Configuring a share on vSAN File Services
For each share you will need to configure:
A share name – This will be the path set after the namespace in NFSv4 or directly off the shares primary IP in NFSv3.
A Storage policy – Adjusting the RAID level here can help optimize capacity or resilience.
Share Warning threshold – This is a soft quota that will generate a vSAN health alarm when reached.
Share Hard quota – This is a hard quota. At the point this is reached writes will fail until data is deleted or this quota is raised.
Labels – These can be useful for categorizing a share (adding what department) data classification (compliance or security level) or other organizational methods. These can also be auto-generated when being created by Kubernetes making it easier to identify the MongoDB share the developers are having issues with etc.
Network access controls – These are IP based access control lists for who has read or write access to the shares (along with the usual root_squash ability for systems that need it and can only connect as root, but do be aware of the security implications of using this).
https://youtu.be/q2jRd2RBIaw
Upgrading vSAN File Services
This one is pretty Simple. vSAN will phone home and look for new versions of the file services OVF package. If the environment lacks internet connectivity from the vCenter a proxy can be used, or the file can be manually downloaded and uploaded to the vCenter.
According to a study by Google, The annual incidence of uncorrectable errors was 1.3% per machine and 0.22% per DIMM. This rate rises to 1.7–2.3% after seeing corrected errors. Hard errors are caused by physical factors, such as excessive temperature variation, voltage stress, or physical stress brought upon the memory bits. Soft errors are random bit flips, typically associated with alpha particle radiation, solar winds and are correctable.
As the number of DIMMs and density of them increases, I suspect this only gets worse and rapidly approaches 100% if I have something important to work on.
Odds of me seeing this increase to 100% the closer I am to recording a Demo
Now, what happens with a VMware host, when the CPU detects unrecoverable errors for memory? This depends on who gets the bad bit:
-VMkernel: Crash (i.e. PSOD) the ESX host unless the kernel is within MCE Safe context.
VMM: Kill the VM. (The Virtual Machine should restart).
User space: Kill the user world (Most processes can be restarted).
Now, what if we want some protection? It’s worth noting that using ECC memory provides some basic protection (A single bit randomly flipping), and more importantly, provides awareness against larger protections through active scrubbing (So we don’t commit corrupt data to disk). If we want to mitigate larger failures (Such as an entire memory device on a DIMM or a DIMM itself) we need to look for more advanced protection methods.
Memory Mirroring: This is pretty simple and fairly expensive. This involves mirroring all DIMMs, so that in the event of a DIMM failure the server will keep on running. This is only outmatched by more extreme triple-redundant quorum/voting systems used on spaceflight computers. This is only considered for mission-critical systems in extremely difficult to reach places (Submarine, diamond mine, etc).
Single Device Data Correction (SDDC) – Out of the normal 18 memory devices on a DIMM you kee 1 device for CRC and 1 device for parity. If one if the devices fails, its data can be reconstructed. This is called single-device data correction (SDDC). Think of this a bit like RAID 4 (dedicated parity device) with checksums stored on a dedicated device also rather than with the block of data. Note a +1 option, effectively keeps a “hot spare” device so that after a failure is mitigated, you can support another failure. For Intel The Silver/Bronze SKUs offer an adaptive variant called Adaptive Data Correction (ADC), at Bank granularity.
Double Device Data Correction (DDDC) – This is where things start to get fancy and weird. By combining two 4x DIMMs into the same memory channel you can run a double parity scheme across both devices. This comes with performance impacts (Memory throughput seems to be the main issue). This doesn’t seem to be recommended for high throughput applications (HPC).
Adaptive Double DRAM Device Correction (ADDDC) – New with the Intel Scalable series processors (2017), this enables the ability to avoid the performance pre-failure that the DDDC design normally imposes. Note this feature doesn’t work with 8x DIMM layouts (smaller 8 and 16GB DIMMs from what I’ve found). For Intel, the Platinum/Gold SKUs offer Adaptive Double DRAM Device Correction (ADDDC).
Other weird OEM options – You will find stuff like hot spare DIMMs, and exotic additional bit ECC, how often scrubbing is performed etc. Be careful with this stuff and talk to your OEM about the expected performance impact.
Address Range Partial Memory Mirroring – This is an intel specific technology with a bit of variety on the implementation depending on the OEM. Unlike DIMM mirroring (which is transparent) this requires a OS –> Firmware interface for the OS to be aware of. In this case this is what the vSphere reliable memory feature enables. How this works under the hood is kernel processes flagged for usage of this will use this memory and be protected up to and including a full DIMM failure. This feature requires Intel Xeon Platinum and Gold processors SKUs.
Let’s see what this looks like in VMware!
You can look up how much memory is considered reliable by using the ESXCLI hardware memory get command.
Before turning on feature:
[root@h2:~] esxcli hardware memory get
Physical Memory: 549657530368 Bytes
Reliable Memory: 0 Bytes
NUMA Node Count: 2
After turning it on:
[root@h2:~] esxcli hardware memory get
Physical Memory: 480938061824 Bytes
Reliable Memory: 68619579392 Bytes
NUMA Node Count: 2
On boot I can see that a bit of DRAM has been borrowed for “reliable memory” (54GB). Given this is 1/8th of the memory in the host that is a trade off (12.5%) but it’s is something for mission critical applications that might be worth considering. Digging around 12.5% is normal for a 13Gen server. Note this memory overhead comes 100% out of the first NUMA node (ESXTOP will confirm this).
It’s worth noting that more than the kernel can use this feature. Virutal Machines can be configured for it by following KB2146595 and using the VMX flag sched.mem.reliable = "True"
If you reserve 30% or more of a CPU you could trip an alarm called “Significant imbalance between NUMA nodes detected”.
How much should be reserved? The guidance in 5.5 was for at least 3GB, but if virtual machines are using this, or extensive services are being used ona host more may be needed.
There is a bit of variety in the OEM implementations.
Dell – The servers I tested this with by default grab either 12.5% or 25% of my hosts memeory depending on if I use the fault resilient mode, or the NUMA fault resilient mode.
Fujitsu – Supports 4GB + %. Can be defined in UEFI (which makes me think other OEM’s might have unsuppoprted hacks to alter this in UEFI basd on Intel’s documentation).
SuperMicro – I found no mention of partial memory mirroring in their RAS guide. Note their RAS guide is a great read on the other parity based protections.
Should I configure reliable memory?
You fundamentally have to ask yourself a few questions:
What am I paying for RAM, and what is the overhead going to be? In the case of the Dell functionality I tested it appears the BIOS is reserving 64GB. Looking at 3rd party memory prices this is going to run me in the us about $439. Looking at the spot price of memory recently it seems DRAM pricing is hitting new lows. Maybe it is worth sparing some to increase residency for mission critical clusters?
What is my tolerance for a host failing from a bad DIMM? For this you need to look at your estimated DIMM failure rate, and consider the odds that something important in kernel space is crashed by the DIMM failure (most user world things and virtual machines will reboot if they hit a non-recoverable memory error). If this is Test/Dev I might not care, if I’m running an Oracle RAC cluster that backs the ERP for a fortune 50 company I might have more sensitivity.
Is HA and/or application clustering “good enough protection?
Should I extend this to Virtual Machines? The VMX flag allows configuration of virtual machines to attempt to fit into the reliable memory space. I’m not sure what happens when the host is given 64GB of reliable memory and I try configuring a 100GB reliable memory VM (More testing needed).
Is 4GB good enough? Some platforms (HPE) offer the ability to configure 4GB or 4GB + xx%. By lowering what is protected (but lowering the cost overhead) a blend of risk mitigation and cost control may be “good enough” for many.
Would I rather mirror a virtual machine between two hosts (SMP-FT) and just pay the extra overhead?
Is there a particle accelerator or evil supervillain lab next door? If the server will be operating near a major source of alpha particle radiation it may be worth considering full mirroring (or shielding the server!)
This is going to be a short post collecting a few tricks to unlock some bottlenecks in storage networking that may grow over time:
Unfortunetly a lot of troubeshooting of networking performance stops earlier than it should. Two common incomplete troubleshooting workflows I’ve seen:
Someone checks that network utilization on a host isn’t near the link speed and says “network not the bottleneck”.
Someone calls the networking team and they look at the switchports utilization based on SNMP polling, or do a quick “Show interface” and don’t see obvious port errors (CRC, drops, giants etc). They proudly close the ticket as “Switches are fine!”
Buffer Configuration Considerations
In one of my labs where we have a Nexus 9000 series switch we found performance was looking a bit limited. Seeing higher than expected re-ransmits we dug into it deeper. We dug deeper into buffer utilization. Discovering that the default mesh configuration was limiting buffer access to 500 KB per port, we adjusted the buffers using the qos ns-buffer-profile ultra-burst command. This signifigantly opened up performance, reducing TCP incast inssues (which cause retransmits) and brought performance more in line with what we would expect for the cluster. For anyone looking for more inormation on this command (and how to look at buffers) see the QoS Guide. Note for solving buffer contention different switches will have different options for configuring buffers, priortizing which flows to drop first, and allocating buffer to ports. In other cases it may be simpler to just buy switches with deeper buffers to begin with. Rather than trying to chop apart a 12MB-40MB buffer, simply purchasing a switch with an 8GB buffer can avoid a lot of the need for buffer management consideration.
This command will be more useful than the “display buffer usage” as that only tracks usage over a 5 second rolling outage, vs the violation tracker that the interface counter can track (Which will detect very short microbursts that may be causing buffer full and retransmits conditions nad latency). Note the default buffer threashold is 70%.
burst-mode enable appears to be a similar command to the ultra-burst buffer configuration and is recomended for cases that include “Traffic enters a device from multiple same-rate interfaces and goes out of an interface with the same rate.” Given this scenario is exactly what we would see from TCP incast (multiple vSAN hosts trying to talk to the same host and filling a buffer), this is likely something you would want to turn on. As I don’t have one of these switches in my lab, I’d love any feedback anyone has from trying this command. If anyone from HPE Networking is reading this, feel free to reach out.
TCP dispatch queues tuning
In another example in the lab, a test of raw throughput was coming up short. A review of the back end disk groups showed a lack of congestion (latency was low, write cache fill rate was low). A review of network utilization showed only 30% utilization on the link speed, but high latency (20ms+ between the nodes).
Investigation showed that the throughput was bottlenecking on a single threaded TCP process (CPU for attached world at 100%). By raising the TCP RX queues from the default of 1 to 4, this eleminated this as a bottleneck and returned performance to expected levels.
It’s worth noting that Niel’s blog on vMotion tuning reported higher throughput per stream than I saw (His blog reports 15Gbps per stream). This may be a result of my lab hosts using inexpensive cheaper Intel 5xx series NICs that lack the advanced offloads that the Intel 700 or 800 series cards have. Mellanox CX Series cards also have similar capabilities. Without these offloads, more CPU is needed to push the same throughput and this would compound together to bring the performance ceiling even lower with the cheaper NICs.
Summery
For anyone seeing bottlenecks on lower-cost NIC’s, or wanting to push more than 15Gbps per host of vSAN traffic, keep an eye on this setting, and talk to GSS if you are concerned this default may be causing a bottleneck. For new hosts I’d strongly consider smarter NIC’s that contain hardware LRO/TSO, RSS VxLAN GENEVE offload capabilities and make sure that your driver and firmware are both up to date. Note in a future release this default may change.
If you have any feedback on these commands (or questions on other commands or switches!) reach out to me on twitter @Lost_Signal
From time to time I get oddball questions where someone asks about how to do something that is not supported or a bad idea. I’ll often fire back a simple “No” and then we get into a discussion about why VMware does not have a KB for this specific corner case or situation. There are a host of reasons why this may or may not be documented but here is my monthly list of “No/That is a bad idea (TM)!”.
How do I use VMware Cloud Foundation (VCF) with a VSA/Virtual Machine that can not be vMotion’d to another host?
This one has come up quite a lot recently with some partners, and storage vendors who use VSA’s (A virtual machine that locally consumes storage to replicate it) incorrectly claiming this is supported. The issue is that SDDC Manager automates upgrade and patch management. In order to patch a host, all running virtual machines must be removed. This process is triggered when a host is placed into maintenance mode and DRS carefully vMotions VMs off of the host. If there is a virtual machine on the host that can not be powered off or moved, this will cause lifecycle to fail.
What about if I use the VSA’s external lifecycle management to patch ESXi?
The issue comes in, running multiple host patching systems is a “very bad idea” (TM). You’ll have issues with SDDC Manager not understanding the state of the hosts, but also coordination of non-ESXi elements (NSX perhaps using a VIB) would also be problematic. The only exception to using SDDC manager with external lifecycle tooling tools are select vendor LCM solutions that done customization and interop (Examples include VxRAIL Manager, the Redfish to HPE Synergy integration, and packaged VCF appliance solutions like UCP-RS and VxRACK SDDC). Note these solutions all use vSAN and avoid the VSA problem and have done the engineering work to make things play nice.
JAM also not supported!
Should I use a Nexus 2000K (or other low performing network switch) with vSAN?
While vSAN does not currently have a switch HCL (Watch this space!) I have written some guidance specifically about FEXs on this personal blog. The reality is there are politics to getting a KB written saying “not to use something”, and it would require cooperation from the switch vendors. If anyone at Cisco wants to work with me on a joint KB saying “don’t use a FEX for vSAN/HCI in 2019” please reach out to me! Before anyone accuses me of not liking Cisco, I’ll say I’m a big fan of the C36180YC-R (ultra deep buffers RAWR!), and have seen some amazing performance out of this switch recently when paired with Intel Optane.
Beyond the FEX, I’ve written some neutral switch guidance on buffers on our official blog. I do plan to merge this into the vSAN Networking Guide this quarter.
I’d like to use RSPAN against the vDS and mirror all vSAN traffic, I’d like to run all vSAN traffic through a ASA Firewall or Palo Alto or IDS, Cisco ISR, I’d like to route vSAN traffic through a F5 or similar requests…
There’s a trend of security people wanting to inspect “all the things!”. There are a lot of misconceptions about vSAN routing or flowing or going places.
Good Ideas! – There is some false assumptions you can’t do the following. While they may add complexity or not be supported on VCF or VxRAIL in certain configurations, they certainly are just fine with vSAN from a feasibility standpoint.
Routing storage traffic is just fine. Modern enterprise switches can route OSPF/Static routes etc at wire-speed just fine all in the ASIC offloads. vSAN is supported over layer 3 (may need to configure static routes!) and this is a “Good idea” on stretched clusters so spanning tree issues don’t crash both datacenters!
vSAN over VxLAN/VTEP in hardware is supported.
VSAN over VLAN backed port groups on NSX-T is supported.
Bad Ideas!
Frank Escaros-Buechsel with VMware support once told someone “While we do not document that as not supported, it’s a bit like putting peanut butter in a server. Some things we assume are such bad idea’s no one would try them, and there is only so much time to document all bad ideas.
Trying to mirror high throughput flows of storage or vMotion from a VDS is likely to cause performance problems. While I”m not sure of a specific support statement, i’m going to kindly ask you not to do this. If you want to know how much traffic is flowing and where, consider turning on SFLOW/JFLOW/NetFlow on the physical switches and monitoring from that point. vRNI can help quite a bit here!
Sending iSCSI/NFS/FCoE/vSAN storage traffic to an IDS/Firewall/Load balancer. These devices do not know how to inspect this traffic (trust me, they are not designed to look at SCSI or NVMe packets!) so you’ll get zero security value out of this process. If you are looking for virus binaries, your better off using NSX guest introspection and regular antivirus software. Because of the volume, you will hit the wire-speed limits of these devices. Outside of path latency, you will quickly introduce drops and re-transmits and murder storage traffic performance. Outside of some old Niche inline FC encryption blades (that I think Netapp used to make), inline storage security devices are a bad idea. While there are some carrier-grade routers that can push 40+ Gbps of encryption (MLXe’s I vaguely remember did this) the costs are going to be enormous, and you’ll likely be better off just encrypting at the vSCSI layer using the VM Encryption VAIO filter. You’ll get better security that IPSEC/MACSEC without massive costs.
Did I get something wrong?
Is there an Exception?
Feel free to reach out and lets talk about why your environment is a snowflake from these general rules of things “not to do!”
This post has been a long time coming, as Network Interface Cards are an often overlooked component. Many people have mistakenly assumed all NIC’s are the same or are simple commodities. Note, that most of this advice will also apply as generic advise for vSphere, and ethernet storage. Here is a short list of features and considerations when picking a network interface card. I’m hoping this series will spawn out into more information on picking switches, as well as troubleshooting of NICs and switches.
Offload Features
LRO/LSO – Large Receive Offload, and Large Send Offload allow for packets to be broken up when transmitting and consolidated. Note: TCP segmentation offload (TSO) is a very common form of LSO and you will often see these terms used interchangeably. This provides improvements in CPU overhead. The VMware Performance Team has a great blog showcasing what this looks like for virtual machines. LRO can benefit CPU overhead on 64KB workloads by as much as 90%.
Receive Side Scaling (RSS) – Helps distributed load across multiple CPU cores. At higher throughput operations it is possible that a single CPU thread can not fully saturate larger network interfaces. In sample testing, a 40Gbps NIC could only use 15Gbps when using a single core. RSS is also critical for VxLAN/NSX performance. Note RSSv2 is supported by a limited subset of cards (This appears to allow balancing at a more granular level).
Geneve/VxLAN encapsulation support – For customers using NSX, hardware support for overlays again helps increase performance and should be added to the shopping list when selecting a NIC.
Converged over Ethernet (RCoEv1/RCoEv2) – While vSAN doesn’t yet, support RDMA, vSphere VM’s, iSER (iSCSI RDMA Extensions) support is shipping today, and hopefully in the future additional support will come for other traffic classes. RDMA significantly lowers latency, lowers CPU usage and increases throughput while keeping CPU usage down. Note, RCoE avoids the use of TCP, while iWARP (a competing standard) runs RDMA over TCP. RCoE requires not only NICs that support it, but also physical switches to support it. Mellanox is a popular vendor for both NICs (X4) and switches as they have a long history of working with RDMA.
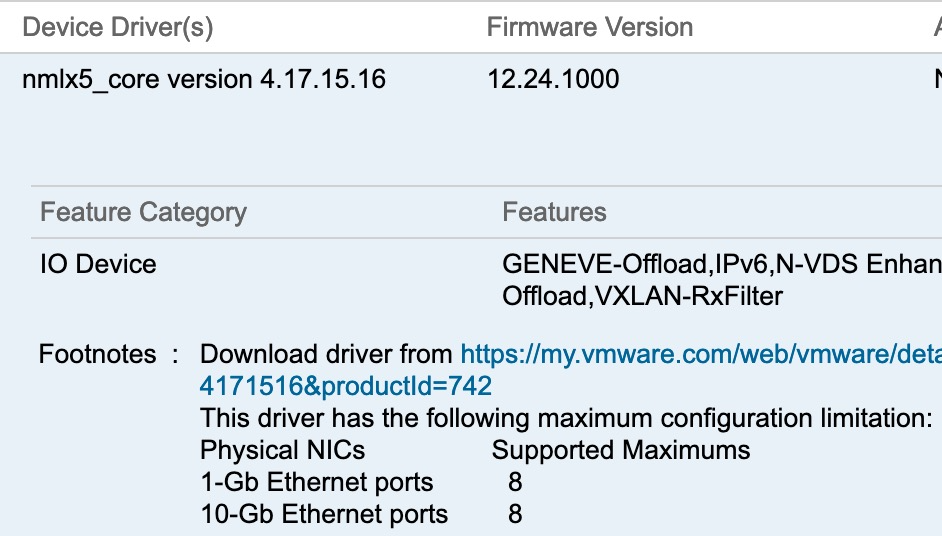
NSX-T Virtual Distributed Switch (N-VDS). NICs that support this will feature “N-VDS Enhanced Data Path” support in the vSphere VCG. This includes the ability for Traffic flow over NUMA aware Enhanced Data Path. While this is normally something reserved for NFV workloads, the gains in throughput are massive. This Blog is a good starting point.
Turn this path up to 11
MISC CNA/Storage Options.
iSCSI HBAs have come in and out of vogue over the years. In general, I have some concerns with the quality of the QA the vendors are doing for this feature that sees such little usage now that the software initiator is the overwhelming majority of the market. FCoE has been removed/deprecated from some Intel NICs and in general, is falling out out favor. A software
FCoE software initiator now exists, but in general, the fad of FCoE (Which was always a bridge technology) seems to be slowly going away. For those still using FCoE CNA’s be sure to make sure that vVols secondary LUN support is available.
NVMe over Fabrics (NVMe-oF) – Support for NVMe over ethernet fabric is slowing gaining interest in customers looking for the lowest latency possible. While possible to run over Fibre Channel, 100Gbps RDMA Ethernet is also a promising option.
Other Conisderations
Supported Maximums – Not a huge issue for most, but some NIC’s have caveats on the maximum supported number that can be placed in a host. This is often tied to driver memory allocations. This information will be found in the vSphere maximums as well as in the notes on the VCG entry for a NIC.
Link Layer Discovery Protocol LLDP – Technically normally a software feature, but on some NIC families this is bizarrely made a hardware feature. This can have…. interesting results depending on the implementation.
Nothing to see here, rogue ARPs are normal!
Stable/Fast Driver Firmwareand engineers to maintain this – I’m not sure why I have to list this as a “NIC feature” but it is. There are NIC’s out there that have had hilariously unstable firmware for years (Note this isn’t a vSphere issue, but a general issue across OS platforms). Some vendors will take an issue and rapidly RCA it in their testing lab. Others will ask you to be a crash test dummy and run debug drivers in production “until it happens again” Questions to ask an OEM are “If we have an issue do you have the hardware to recreate this, and were physical? is this lab?”. If you are repeatedly being asked to run async drivers (that are not tested/validated by VMware) this may be a sign that this vendor doesn’t have adequate engineering behind this card.
The PSODs are a feature?
Flow control – This is something you really only should be using on 1Gbps, otherwise turn it off. It’s not a problem, and there are frankly are better ways (CoS/DSCP) to prioritize traffic under contention.
Management APIs for CIM Providerand OCSD/OCBB Support – This can allow for better out of band monitoring of this NIC. If there are not good ways to interigate health and pull logging of the card, recreating issues can be painful.
Wake on LAN – Really you should be waking servers using the out of band management, but ocasionally there is a use for this.
So what do these features mean for a HCI Architect?
Lower host CPU usage means more CPU available for processing storage and running virtual machines enabling increased virtualization consolidation.
Higher Throughput per core (as a result of LRO/TSO) means that higher performance per core can be achieved by reducing uncessary CPU usage. This allows faster resync operations (commonly 64KB), as well as higher throughput available. LRO/TSO/RSS help prevents single-threaded networking processes from becoming bottlenecks.
Lower Packets Per Second (PPS) – By consolidating packets with TSO, fewer packets must transverse the physical switches. Many Switch ASICs will have limits as to how many PPS they can process and will be forced to delay packets negatively impacting performance.
Caveat Emptor – Some NIC’s have had a troubled history with these features, and may require driver/firmware updates to make stable. Some vendors may label a feature as offload, but in reality still, process them in CPU. Some features may only be supported in specific driver versions, or might even be quietly deprecated and scrubbed from the datasheets. Note, the suubtle humor of release note writers can not be understated. “may lead to connectivity issues” may translate as “cause the host to crash, and cause a plague of locusts to infest the datacenter”. As always, trust but verify.
Feedback – Did I get something wrong? Did I not properly abreviate NVM over Fabrics? Is FCoE still the future of storage 10 years later? Reach out to me on twitter @Lost_Signal and lets continue this conversation.
The short response is no. You should avoid using these devices with vSAN, and in general with virtualization or storage traffic.
They were designed for a time when low utilization of physical servers or low-density virtualization was the norm. At the same time, the price for 10Gbps ports on fast switches was incredibly expensive.
Move any servers with bursty traffic flows such as storage arrays and video endpoints off of the FEX and connect them directly to the base ports of the parent switch.
Common questions that have come up at VMworld and other discussions:
Q: why should I listen to a guy who does storage and virutalization about networking?
A: I don’t disagree. How about one of the Co-Founders of the company that built the FEX?
As a co-founder of Nuova Systems, where we invented FEX, I heartily agree with this sentiment.
A: This isn’t really a VMware problem. Storage or other large traffic flows like vMotion suffer on Cisco FEX devices. Note other east/west heavy traffic flows suffer in light buffered oversubscribed environments. vMotion, and NSX are also not going to perform there best without real switch ports.
Q: What are some model numbers for the device?
A: Devices:
N2K-C2148T-1GE
N2K-C2224TP-1GE
N2K-C2248TP-1GE
N2K-C2232PP-10GE
N2K-C2232TM-10GE
N2K-C2248TP-E-1GE
N2K-C2232TM-E-10GE
N2K-C2232TM-E-10GE
N2K-C2248PQ-10GE
N2K-C2348UPQ-10GE
B22
Q: My networking team told me they are just like an external line card for a switch chassis?
A: Your networking team is incorrect. A real switch port can send traffic to another port without hair-pinning through another device. It’s arguable that a hub would provide a more direct route for packets from one port to another than what the FEX product line offers. Modern switches also offer much larger buffers that can help mitigate TCP incast and other issues that you will see at scale.
Q: How do I determine if my networking teams have deployed Cisco FEX devices?
A: This can be difficult without physical inspection to known issues with Cisco Discovery Protocol) not working correctly with some configurations of the devices. One sign is if the port on the switch has incredibly high designations 100/1/1 you may be looking at a FEX. It’s best to have your data center operation teams inspect the racks, and take note of model numbers in the same way you would have them physically inspect for cardboard or other things you don’t want in your datacenter. Ultimately the best solution is preventative. Talk to your networking teams about the risks of using FEX devices before they are deployed.
Q: What are some alternatives to look at?
I’m happy to take comments from other networking people about this but I’ve seen two general choices that customers use instead.
For Cisco customers looking for a device that need FCoE, the Nexus 56xx, 6000, and 7000 offer real switch ports as well as larger buffers. Note: older Nexus 50xx and 55xx have relatively small VoQ buffers that tend to not scale well with larger clusters.
For customers not needing FCoE support (which should be most customers in 2019), the C36180YC-R offers:
I had previously discussed in a rather click bait title of an article how falling storage prices were making vSAN cheaper. As the economics of flash + perpetual socket licensing made the cost per GB for vSAN (and cost per VM) go down over time. It’s 2019 and I wanted to example what those old hosts that need to be replaced might look like.
2014/2015 host
2 x 8 core processors (Intel Xeon v3)
3.6TB to 6TB RAW capacity (3 or 5 x 1.2TB 10K RPM drives) with 400-800GB of SATA/SAS SSD Cache.
128 GB RAM.
4 host cluster
Now, this host would require two sockets of vSAN and vSphere licensing for a total of 8 sockets.
Now going into 2019, we are ready to replace these nodes and deploy new ReadyNodes.
1 x 16 core processors (Xeon Scalable, or AMD EYPC now as a very viable option).
256 GB of RAM
32TB of RAW NVMe with 2 x 800GB of NVMe Cache.
8 host cluster
Let’s look at a few improved density capabilities:
Single Socket, because realistically this system should be able to run more than twice the workloads as the older processor.
Less overhead. The overhead for CPU as a % of the cluster for N+1 capacity planning drops from 25% for a four-host cluster, to a 12.5% for an 8 host cluster.
AMD EPYC allows for use of all memory channels and PCI lanes so for workloads that will fit within a processor scaling out has some natural efficiency.
Single socket cuts the licensing count in half for hosts, allowing me to run twice the hosts for the same licensing cost.
All Flash lets me use Erasure Codes along with Deduplication and compression and the 5-8x more RAW capacity mean I can store a LOT more data. RAID 6 vs FTT=2 mirroring cuts overhead in half.
Performance Improvements as a result of the all NVMe configuration along with code improvements going from older to newer vSAN IO path code.
A couple other big wins here:
1. Unlike a storage array or appliance I didn’t have to re-buy licensing. Nothing was “thrown away” in this transition. No sales guy came out and scared me with a scary renewal before offering me some insane trade in play to some new platform I’m not familiar with. At no point in the purchase of new hardware did I feel the process should be described as a “Barking Carnival” or a “Goat Rodeo”. I might upgrade some license versions, but the existing value and that delta cost remained the same and no one was trying to force me to make a transaction.
2. I doubled my host count without doubling my licensing or support renewals. Say it with me “I should expect MORE VALUE from my HCI solution as the investment ages, not less!”.
3. I increased my compute capabilities with the same socket count by 4x or more. Inversely if I was a large shop not growing, I might even consolidate my fleet, shift some licenses to cover DR, or other environments to expand on my vSAN success. I can even split up these nodes to do this. A traditional storage frame unfortunately can’t be cut into three pieces and reused at 3 sites.
4. I massively increased by storage performance and capacity footprint. The old hardware may get phased out for a lab, used for DR, or sent to recycling but my vSAN investment carried forward through this growth. No one at VMware “tax’d” me for adding hosts, cores, performance, or capacity to expand my environment.
Another year another VMworld. I’ve got a few sessions I will be presenting:
HCI1473BU
The vSAN I/O Path Deconstructed: A Deep Dive into the Internals of vSAN
???
Mystery Session: 7/27 at 3:30PM
HCI1769BU
We Got You Covered: Top Operational Tips from vSAN Support Insight
HCI3331BU
Better Storage Utilization with Space Reclamation/UNMAP
The vSAN I/O Path Deconstructed is an interesting inside look at the IO path of vSAN and the reasoning behind it.
We Got You Covered: Top Operational Tips from vSAN Support Insight shows off the phone home capabilities of vSAN and can help address your questions about what and how this data is used. We are also going to discuss how you can leverage similar views of performance as GSS and engineering to identify how to get the most out of vSAN.
HCI3331BU is a session that has been years in the making for me. “Where did my space go” is a question I get often. We will explain where that missing PB of storage went and how to reclaim it. The savings from implementing UNMAP should be able to fund your next VMworld trip!
Lastly, I’ve got a mystery session that should be unveiled later. Follow me on Twitter @Lost_Signal, and I’ll talk about what it will be when the time comes.
Pete and I will be recording for the vSpeakingPodcast Podcast LIVE! At the HCI Zone (Found near the VMware booth). We’ve got some new guests as well as some favorites lined up.
Some guidance for the tool has been included on how to use it are in the design and sizing guide on StorageHub.
A lot of partners like using RVtools (A great way to make a simple capture of an inventory, health, and configuration) as a means to collect storage capacity information, as well as a snapshot of compute allocations.
If you have a large number of powered off VM’s have a serious discussion if they will all be started or needed at any time. If not, consider excluding them from compute sizing.
Use the health tab and look for Zombie VM’s and see if these cold VM’s can be deleted or migrated out.
Look for open snapshots, and see if these need to be collapsed (which can save space).
Be aware of the difference in the two storage metrics (allocated vs. consumed MB). If you intend to keep using thin provisioning, you do not need to size for all of the allocated. In the video, this is a significant capacity difference.
If the existing solution has VM’s tied to storage demands (Storage management VMs, VSA’s) that will be deprecated by vSAN be sure to exclude them.
Have a serious discussion on if the vCPU to physical core ratio is “working” or if they see performance issues. I’ve seen both people be too conservative (1:1 in test dev) and too aggressive (20:1 for databases!). You can see the existing ratio’s on the host tab.
Pay attention to CPU generations. Vintage Xeon 5500 will be crushed clock for clock by new EPYC processors.
Realize you can change the CPU configuration (Cluster advanced options). Some people may want to optimize their CPU model for licensing (commonly 16 core for windows, or possibly lower core but higher clock for Oracle). You can change these assumptions.
Be sure to check out the health tab, and look through the host configs. Make sure NTP is set up on hosts! Use this as an opportunity to see if the existing environment is even healthy.
Have any more tips and tricks? Check out the comments section below!
UPDATE: https://kb.vmware.com/s/article/53749
VMware and Intel have a KB for workarounds on this issue.
I was reading Bob Plankers colorful complaints about his Intel X710/XL710/X722/XXV710 family of NICs and figured I’d do some digging and ask around on people I know who have them as well as summarize some things I learned from using them as a customer.
A few observations:
These problems are not specific to vSphere. People running Linux and Windows on bare metal ran into these issues
While a lot has been focused on the LRO/TSO issue, there is another separate issue tied to LLDP and duplicate mac addresses being created.
First Issue LRO/TSO
This KB Sums up the issue quite well by pointing out that these features can cause PSODs. Checking with some friends who used to be able to reproduce this at the drop of a hat the newest driver/firmware is a lot more stable in this regard, but it can still happen. Some people are leaving these disabled to stay safe, while others are hungry for the small CPU gains these features deliver. How do I remediate it? Beyond manually setting it on the hosts Jase Mccarty has a great script that will do this in bulk for a cluster.
Next up: The case of the disappearing host!
The common symptom is that management on a host will cease to function (Pings will drop) and the host will disappear from vCenter. Sometimes something more catastrophic happens (HA triggers, host isolation is triggered, storage or vMotion fails). If you pay attention closely to LogInsight, you will see your switches are reporting Mac Address Flapping (You are sending your switches syslog into LogInsight, RIGHT?!?)
Sow what’s going on here?
How is VMK0 special
This goes back to the special behavior for VMK0 where it steals the mac address from a physical port. This is handy for new cluster setups where people know the MAC addresses from the OEM providing them before delivery being able to put this in their DHCP reservations and get started without needing to physically touch the hosts to know which one is which etc.
Why is this card special?
This card is unique in that there is a special LLDP agent that runs on the card and intercepts LLDP packets. Previously I associated LLDP with simply sending information on what’s plugged in where (which is why you should turn it on for send/receive with your VDS). In this case, though the LLDP agent will also update where a MAC is located.
Why together does this happen?
The challenge comes when VMK0 moves to a different physical switch port and tries to move the MAC address with it. You get a fun ARP battle between the LLDP agent of the physical port and the VMK0 that is behind a different physical port. A good old fashioned duplicate MAC entry ARP battle ensues, and this is going to manifest itself as a host going offline completely, or flipping back and forth based on the update hold-down interval on the switch. (Side note, any real networking people feel free to correct me on my terminology here I dropped out of my CCNA class in 2008).
Why did I loose more than management (or what am I doing wrong!)?
Given most people use VMK0 for management by vCenter (and for non-VSAN clusters HA heartbeats happen here) this can have a lot of interesting behaviors like loss of management, host isolation response being triggered. This is another great reminder of why you should use datastore heart beating, or VSAN which will not depend on VMK0 for heartbeats.
Also if you are running EVERYTHING on VMK0 (Storage vMotion) which is NOT a recommended practice (isolate storage and vMotion networks!) you could see all of the virtual machines crash and other fun things.
Workarounds?
So there are a few ways to possibly work around this.
You could simply avoid using VMK0 with this card. Either disconnecting it and using a new VMK4 or so forth for whatever it was being used for. This is simple, it’s easy (outside of disconnecting and reconnecting hosts) and doesn’t require you touch the network beyond having one extra IP on the management network to make it easier.
You could change the mac address manually to something in the random VMware MAC address space (Need to clarify if this is supported, but it’s simple enough and avoids this issue). Note that the MAC would be set back if you ever remote and recreate VMK0.
If you trust your networking team, you could try asking they hardcode the MAC address to specific ports in the CAM tables of the switch. I would look at this only as a last resort if operationally you can’t physically change anything on the hosts but need an extreme workaround
*EDIT* It looks like running LACP across the origional physical port and another port will work around the issue. The switch isn’t going to care where the frame comes from, and so this should reduce or ignore the chance of an arp fight. Balancing for VMK0 across physical ports will not be great, but as long as it is is management only you will likely not care too much. (Thanks to Simon for this discussion).
*EDIT* Try putting VMK0 on a tagged NON-Native VLAN. It can’t get in a fight with the LLDP agent for the MAC address if it’s on a completely different broadcast domain (Thanks to Broc Yanda for this idea).
What else is going on that I don’t know about vSphere Networking?