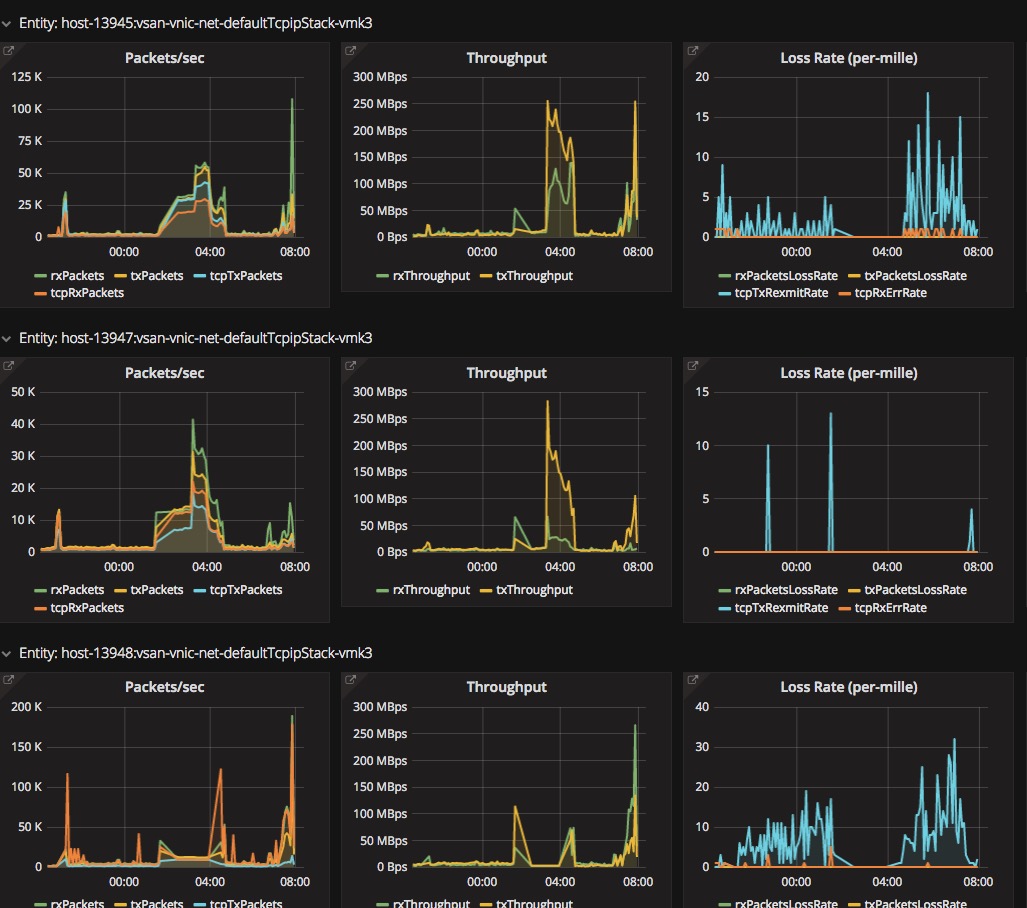
This reddit thread about someone stuck in a non-supported aronfiguration that is having issues made me think its time to explain what supported and partner supported and not supported situations you should be aware of. This is not intended to be some giant pile of FUD that says “Do what John says or beware your doom!”. I wanted to highlight partners who are doing a great job of working within the ecosystem as well as point out some potential gaps that I see customers not always aware of.
I get a lot of questions about storage, and what is supported. At VMware we have quite a few TAP parters and thousands of products that we happily jointly support. These partners are in our TAP program and have submitted their solutions for certification with tested results that show they can perform, and we have agreements to work together to a common outcome (Your performance, and your availability).
There are some companies who do not certify their solutions but have “partner verified” solutions. These solutions may have been verified by the partner, but generally involve the statement of “please call your partner for support”. While VMware will support other aspects in the environment (we will accept a ticket to discuss a problem with NTP that is unrelated to the storage system), you are at best looking for best effort support on these solutions. Other partners may have signed up for TAP, but do not actually have any solution statement with us. To be clear, being in TAP alone does not mean a solution is jointly supported or verified.
VVOLs
VVOls is an EXCELLENT product that allows storage based policy management to be extended to allow seamless management. Quite a few platforms support this today. If your on a storage refresh, you should STRONGLY consider checking that your partner supports VVOL, and you can check by checking this link.
Any storage company who’s looking at supporting VMware deployments at scale is looking at VVOLs. management of LUNs and arrays as you grow becomes cumbersome and introduces opportunity for error. You should ask your VMware storage provider of where they are on support VVOLs, and what their roadmap is. You can also check the HCL to see if your storage vendor is supporting VVOLs by checking here.
VAAI
VAAI is a great technology that allows LUN and NFS based systems to mitigate some of the performance and capability challenges. VCAI is a smaller subset that allows NFS based systems to accelerate linked clone offload. Within NFS a smaller subset have been certified for large scale (2000 clones or more) operations. These are great solutions. I bring this up because it has come to my attention that some partners advertise support of these features but have not completed testing. This generally boils down to 1 of 3 situations.
- They have their submission pending and will have this fixed within weeks.
- Their solution fails to pass our requirements of performance or availability during testing.
- They are a very small startup and are taking the risk of not spending the time and money to complete the testing.
- They are not focused on the VMware market and are more concerned with other platforms.
Please check with your storage provider and make sure that their CURRENT version is certified if you are going to enable and use VAAI. You do not want to be surprised by a corruption, or performance issue and discover from a support call that you are in a non-supported configuration. In some cases some partners have not certified newer platforms so be aware of this as you upgrade your storage. Also there are quite a lot of variations of VAAI (Some may support ATS but not UNMAP) so look at the devil in the details before you adopt a platform with VAAI.
Replication and Caching
Replication is a feature that many customers want to use (either for use with SRM, or as part of their own DR orchestration). We have a LOT of partners, and we have our own option and two major API’s for supporting this today.
One is VADP (our traditional API associated with backups). Partners like Symantec, Comvault, and Veeam leverage this to provide backup and replication at scale for your environment. While it does use snapshots, I will note in 6.0 improvements were made (no more helper snapshots!) and VVOLs and VSAN’s alternative snapshot system provides much needed performance improvements
The other API is VAIO that allows for direct access to the IO path without the need for snapshots. StorageCraft, EMC and Veritas are leading the pack with adoption for replication here with more to follow. This API also provides access also for Caching solutions from Sandisk, Infinio and Samsung.
Lastly we have vSphere replication. It works with compression in 6.x, it doesn’t use snapshots unless you need guest processing, and it also integrates nicely with SRM. Its not going to solve all problems (or else we wouldn’t have an ecosystem) but its pretty broad.
Some replication and caching vendors have chosen to use private, non-supported API (that in some cases have been marked for depreciation as they introduce stability and potential security issues). Our supports stance in this case again falls under partner supported at best. While VMware is not going to invalidate your support agreement, GSS may ask you to uninstall your 3rd party solution that is not supported to troubleshoot a problem.
OEM support
This sounds straight forward, but it always ins’t. If someone is selling you something turnkey that includes vSphere pre-installed, they are in one of our OEM programs. Some examples of this you may know (Cisco/HP/Dell/SuperMicro/Fujitsu/HDS) but all some other ones you may not be aware of smaller embedded OEM’s who produce turnkey solutions that the customer might not even be aware of running ESXi on (Think industrial controls, surveillance and other black box type industry appliances that might be powered by vSphere if you look closely enough). OEM partners get the privilege of doing pre-installs as well as also in some cases offering the ability to bundle Tier 1 and Tier 2 support. Anyone not in this program can’t provide integrated seamless Tier 1/2 support and any tickets that they open will have to start over rather than offer direct escalations to tier 3/engineering resources potentially slowing down your support experience as well as again requiring that multiple tickets be opened with multiple vendors.
Lastly, I wanted to talk about protocols.
VMware supports a LOT of industry standard ways today for accessing storage. Fibre Channel, Fibre Channel over Ethernet, iSCSI, NFS, Infiniband, SAS, SATA, NVMe as well as our protocol for VMware VSAN. I’m sure more will be supported at some point (vague non-forward looking statement!).
That said there have been some failed standards that were never supported (ATA over Ethernet which was pushed by CoRAID as an example) as they failed to gain wide spread support.
There have also been other proprietary protocols (EMC’s Scale IO) that again fall under Partner Verified and Supported space, and are not directly supported by VMware support or engineering. If your deploying ScaleIO and want VMware support for the solution you would want to look at the older 1.31 release that had a supported iSCSI protocol support for the older ESXi 5.5 release or to check with EMC and see if they have released an updated iSCSI certification. The idea here again isn’t that any ticket opened on a SSO problem will be ignored, just that any support of this solution may involve multiple tickets, and you would likely not start with VMware support on if it is a storage related problem.
Now the question comes up from all of this.
Why would I look at deploying something that is not supported by VMware Support and Engineering?
- You don’t have a SLA. If you have an end to end SLA you need something with end to end support (end of story). If this is a test/dev or lab environment, or one where you have temporarily workloads, this could work.
- You are wiling to work around to a supported configuration. In the case of ScaleIO, deploy ESXI 5.5 instead, and roll back to the older version to get iSCSI support. In the case be aware that you may limit yourself on taking advantage of newer feature releases and be aware of when the older product versions support will sunset as this may shorten the lifecycle of the solution.
- You have faith the partner can work around future changes and can accept the slower cadence. Note, unless that company is public there are few consequences for them making forward looking statements of support and failing to deliver on them. This is why VMware has to have an a ridiculous amount of legal bumpers on our VMworld presentations…
- You are willing to accept being stuck with older releases, and their limitations and known issues. Partners who are in VAIO/VVOLs have advanced roadmap access (and in many cases help shape the roadmap). Partners using non-supported solutions, and private API’s are often stuck with 6-9 months of reverse engineering to try to find out what changed between releases as there is no documentation available for how these API’s were changed (or how to work around their removal).
- You are willing to be the integrator of the solution. Opening multiple tickets and driving a resolution is something your company enjoys doing. The idea of becoming your own converged infrastructure ISV doesn’t bother you. In this case I would check with signing up to become an OEM embedded partner if this is what you view as the value proposition that you bring to the table.
- You want to live dangerously. Your a traveling vagabond who has danger for a middle name. Datacenter outages, or 500ms of disk latency don’t scare you, and your users have no power to usurp your rule and cast you out.