Pete Flecha and I co-host the Virtually Speaking Podcast. We both get emails, calls, and texts from various people wanting to start a tech podcast. I figured I'd sort some of the most common advice...Read more
This reddit thread about someone stuck in a non-supported aronfiguration that is having issues made me think its time to explain what supported and partner supported and not supported situations you should be aware of. This is not...Read more
When VASA and storage profiles first came out, I really thought it was not important or over rated for smaller shops. Now that VSAN has broken my lab free of the rule of "one...Read more
After some brief fun setting up distributed switching I'm starting my first round of benchmarks. I'm going to run with Jumbo's first then without Jumbo's. My current testing harness is a copy of...Read more
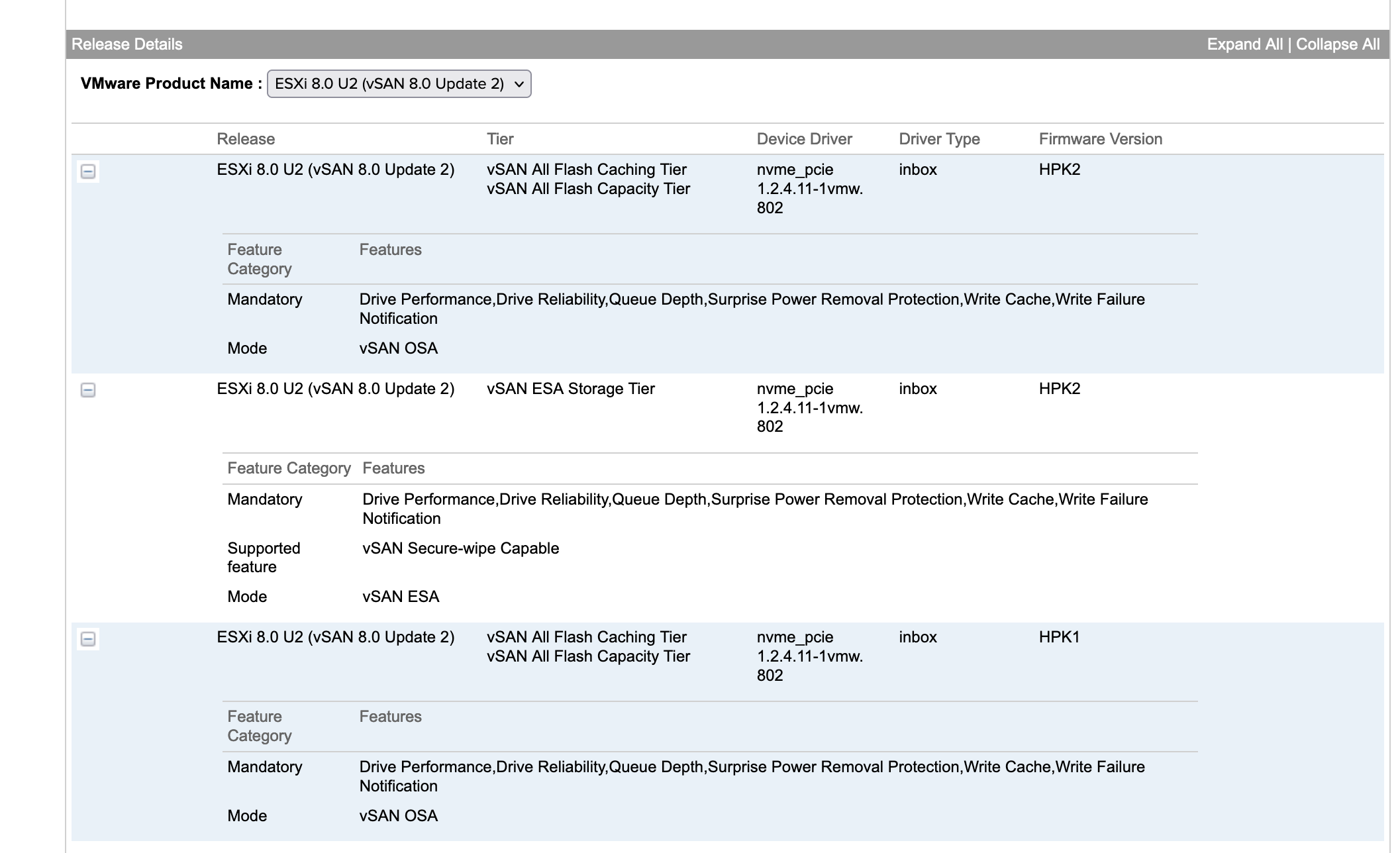
My recommendation is to please disable Intel VMD (Volume Manage Devices) and use the native NVMe inbox drive to mount devices for VMware vSAN going forward. To be clear Intel VMD is NOT a bad technology, but we do not need/want it in the I/O path for VMware vSAN going forward. It can be useful to do RAID on Chip for NVMe boot devices. In addition it was the only method to reliably get hotplug and serviceability (blink lights) prior the NVMe spec being “finished”, hence why it was sometimes used for some older early NVMe vSAN configurations.
Looking at the VCG a number of drive are only being certified using the Inbox driver and not the Intel driver.
You can start with the smallest ReadyNode (Currently this is an AF-2, but I’m seeing some smaller configs in the pipeline), and add capacity, drives, or bigger NICs and make changes based on the KB.
Should I change it?
The biggest things to watch for is adding TONS of capacity, and not increasing NIC sizes, could result in longer than expected rebuilds. Putting 300TB into a host with 2 x 10Gbps NICs is probably not the greatest idea, while adding extra RAM or cores (or changing the CPU frequency 5%) is unlikely to yield any unexpected behaviors. In general balanced designs are preferred (That’s why the ReadyNode profiles as a template exist) but we do understand sometimes customers need some flexibility and because of the the KB above was created to support it.
What can I change?
I’ve taken the original list, and converted it to text as well as added (in Italics) some of my own commentary on what and how to change ESA ReadyNodes. I will be updated this blog as new hardware comes onto the ReadyNode certification list.
CPU
Same or higher core count with similar or higher base clock speed is recommended.
Each SAN ESA ReadyNode™ is certified against a prescriptive BOM.
Adding more memory than what is listed is supported by SAN, provided Sphere supports it. Please maintain a balanced memory population configuration when possible.
If wanting to scale storage performance with additional drives, consider more cores. While vSAN OSA was more sensative to clock speed for scaling agregate performance, vSAN ESA additional threading makes more cores particularly useful for scaling performance.
As of the time of this writing the minimum number of cores is 32. Please check the vSAN ESA VCG profile page for updates to see if smaller nodes have been certified.
Storage Devices (NVMe drives today)
Device needs to be same or higher performance/endurance class.
Storage device models can be changed with SAN ESA certified disk. Please confirm with the Server vendor for Storage device support on the server.
We recommend balancing drive types and sizes(homogenous configurations) across nodes in a cluster.
We allow changing the number of drives and drives at different capacity points(change should be contained within the same cluster)as long as it meets the capacity requirement of the profile selected but not exceed Max Drives certified for the ReadyNode™. Please note that the performance is dependent on the quantity of the drives.
Mixed Use NVMe (typically 3DWPD) endurance drives are best for large block steady State workloads. Lower endurance drives that are certified for vSAN ESA may make more sense for read heavy, shorter duty cycle, storage dense cost conscious designs.
1DWPD ~15TB “Read Intensive” are NOW on the vSAN ESA VCG, for storage dense, non-sustained large block write workloads these offer a great value for storage dense requirements.
Consider rebuild times, and consider also upgrading the number of NICs for vSAN or the NIC interfaces to 100Gbps when adding significant amounts of capacity to a node.
NIC
NICs certified in IOVP can be leveraged for SAN ESA ReadyNode™.
NIC should be same or higher speed.
We allow adding additional NICs as needed.
If/When 10Gbps NIC hosts ReadyNode profiles are released it is advised to still consider 25Gbps NICs as they can operate at 10Gbps and support future switching upgrades (SFP28 interfaces are backwards compatible with SFP+ cables/transceivers).
Boot Devices
Boot device needs to be same or higher performance endurance class.
Boot device needs to be in the same drive family.
TPM
Please just buy a TPM. It is critically important for vSAN Encryption key protection, securing the ESXi configuration, host attestation and other issues. They cost $50 up front, but hours of annoying maintenance to install after the fact. I suggest throwing a NVMe drive at any sales engineer who forgets them off a quote.
The ability to offload snapshots natively to a NFS filer has been around for a while. Commonly this was used with View Composer Array Integration (VCAI) to rapidly clone VDI images, and occasionally for VMware Cloud Director environments (Fast Clone for vApps). There were some caveats to consider:
Up until vSphere 7 Update 2 the first snapshot had to be a traditional redo log snapshot.
VMware blocks storage vMotion for VMs with native snapshots. (You will need to use array replication, and a bit of scripting to move these) which leads to the most important caviot.
A snapshot.alwaysAllowNative = “TRUE” setting for virtual machines was introduced. This allows the virtual machine in NFS datastore with VAAI plugin to be able to create Native snapshots ignoring its base disk is flat one or not.
If the Filer refuses to create a snapshot (Most commonly seen when a filer refuses to allow snapshots while doing a background automated clone or replication on some storage platforms), it will revert to redo log. It is worth noting that “alwaysAllowNative” doesn’t actually prevent this fail back behavior.
Some filers vendors will automatically inject snapshot.alwaysAllowNative = “TRUE” into VMs automatically.
The challenge with this in particular is that it can cause a problem. A Chain that goes from Native, to Redo log back to Native (or Redo Log to Native to Redo log) is invalid and leads to disk corruption!
So what are my options if this is a risk in my environment?
I’ll first off point out that vVols allows offloading of snapshots WHILE retaining support for storage vMotion. It’s fundamentally a bit simpler/more elegant solution to this problem of having natively offloading snapshots.
For most NFS VAAI users this should not be an issue as the filer should just create native snapshots when asked. For platforms that have issues taking native snapshots when other background processes are running, consider disabling that background replication/cloning that is automatically tied to the snapshot tree. If this is not an option consider not using snapshot.alwaysAllowNative and performing full clones, or not using the NFS VAAI clone offload instead. Hopefully in the future there will be a further patch to prevent this issue.
It’s time for a talk on Boot devices. No, we are not talking about SD cards, instead, we are going to talk about encryption and security of boot devices!
One trend lately has been to use PCI-E attached RAID controllers for a pair of M.2 SATA/NVMe devices that boot the server. Example Dell BOSS (Great option!). One challenge for some customers is these controllers often lack encryption support.
You can pay $50 up front, or spend hours of your life in a data center manually trying to add these into a host.
Attestation – You may want to make sure someone didn’t meddle with the binaries, and you can trust the full chain of code used to boot the system including firmware. Secure boot and host attestation require a TPM and cover this. VMkernel.Boot.execInstalledOnly is a setting that will make sure arbitrarily uploaded binaries can’t be executed. Remember you don’t actually have to encrypt the full boot device to protect the binary integrity, this is handled by verifying signatures and UEFI secure boot.
Protecting the configuration file from tampering and or being read – While I find it unlikely anyone is going to physically do anything interesting with my ESXi information (Ohh no, they might learn I use time.vmware.com for NTP /s) there are some paranoid customers out there who have hosts in less than secure locations or consider the IP address of their DNS servers to be highly proprietary. Starting in vSphere 7 U2 the ESXi configuration is encrypted by default, and with a TPM the encryption keys will be securely sealed in the TPM. For more information on this see docs.vmware.com
Summary of a secure boot chain
So with a TPM + Secure Boot + the VMkernel.Boot.execInstalledOnly + TPM sealed configuration encryption a stolen or physically tampered with boot device will not expose sensitive data, or be able to be used to compromise a host.
“Is this enough?”
Personally, I think the above techniques will cover 98% of customer requirements to secure their boot devices and encrypt and sign what matters in a way that someone can’t do anything useful even with physical access to a boot device… For the truly paranoid though I would be remiss to not mention the following ways to 100% encrypt the entire boot device. Note If you go down this path you would still likely want to implement the above steps anyways and will still need/want a TPM, so this is not an “or” option necessarily as anyone this paranoid is going to need/want defense in depth.
Full Device Encryption
But what if my security team is demanding full volume encryption? Well for these cases there are some options.
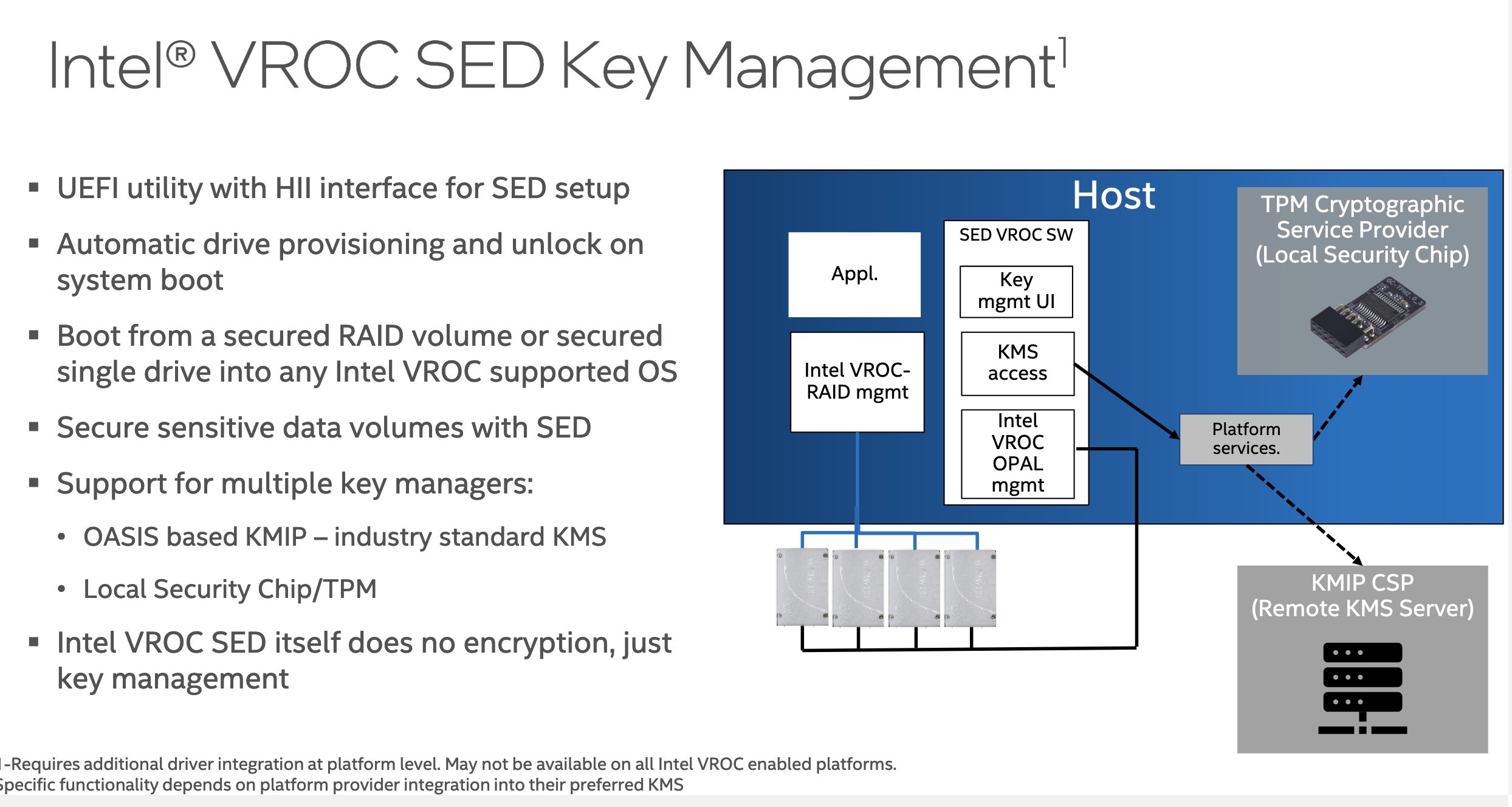
Buy a RAID controller that supports SEDs.
Look at virtual raid-on-chip systems (VROC) for NVMe devices. Intel VMD is one system that can provide RAID 1 for boot devices of NVMe without the need for an add-in card, and also can manage encryption if SED NVMe devices are used. Note you will still need SEDs, as Intel VMD itself doesn’t do the encryption, just passes off the keys to the out-of-band controller (iLO/iDRAC/CIMC etc).
Generally, you will need external KMIP compliant KMS to make this securely work, but again talk to your server OEM.
Final Thoughts
I don’t claim to be the expert on vSphere Security or all compliance scenarios. I would love to hear your feedback and concerns. I’m on Twitter @Lost_signal.
I’m going to keep a blog of sessions and Events I”m checking out and interested in for VeeamOn2022. This will get updated as the week goes on (and may serve as the basis for some Podcast interviews).
Object First
I’ve been tracking out of the corner of my eye ObjectFirst.com as a stealth project. They seem to be building “the best backup optimized object storage system” (or something like it). I have few details and a few theories but am strongly looking forward to the announcement on Monday.
Lab Warz
I still remember the first time I sat down for Veeam’s quirky take on a competitive hands on lab competition. The quirky theming, practical skill testing, and adrenaline pumping “time to do this fast!” feeling was unlike anything I’d ever seen at a conference. I see this listed as virtual only so I look forward to seeing if I can barrel roll through it without too shameful of a score. Even if you don’t feel up to the challenge see if you can learn a thing or two about some features you might be able to find value in.
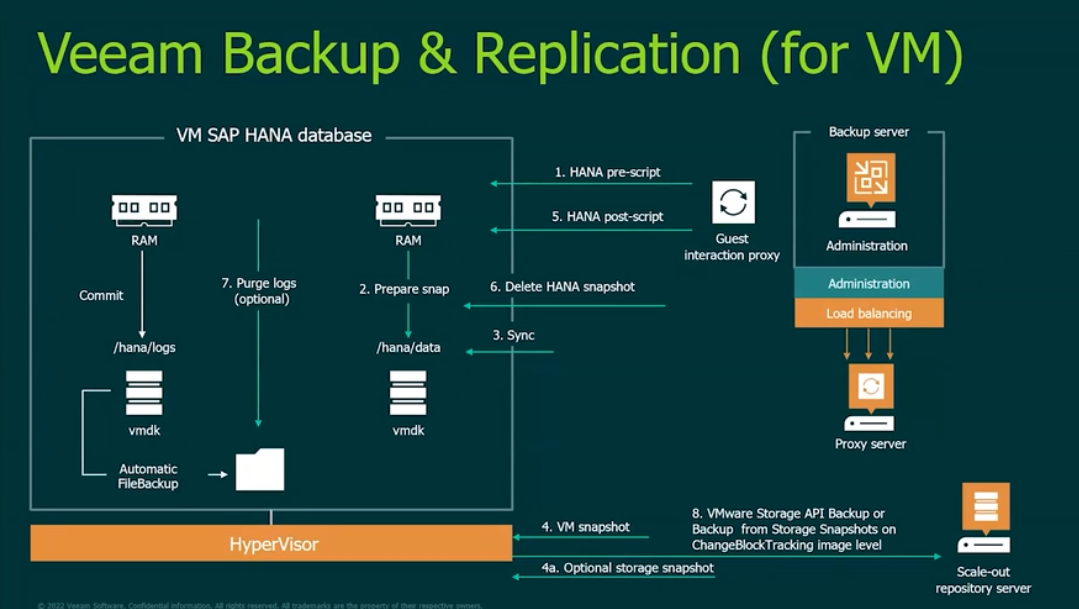
Veeam Plug-in for SAP Now and Later
In a former life I used to deal with application level recovery for various applications ranging from the usual suspects (Exchange, SQL, Oracle) to a few weirder ones. I like checking out occasionally the backup and recovery of virtualized applications that I never operated. It exposes me to challenges that are the similar (distributed state concerns) but also the uniqueness of metadata and blending of VADP/CBT and native tooling. Way too many application backups end up maintained by scripts by DBA’s with dubious alerting and it’s good to see how Veeam is working with SAP and their Backupint framework to offer protection in a way that is supported and allows for consistent restores while still using fancier hypervisor and storage level snapshot offload. One unique workflow I wasn’t familiar with was as “restore license key” on restore which seemed like a pretty nice thing to include as restoring state often includes small things people forget about.
Debanjan Banerjee does a great job walking through how the different pieces come together, and it serves as a good reminder of why virtualizing SAP is always a good idea.
I tweeted this out while in Prague for the Veeam Vanguard Summit, and I’m overdue on writing out my thoughts on the topic of how do I recover quickly a 40TB database virtual machine.
When talking about having different SLAs for products or services you often hear “Good, Better, best” as the segmentation of options based on budgets and requirements. When it comes to architecture deployed for recovery from backup and replication sadly I often see people instead debate between:
“bad, awful, flaming dumpster fire” as their 3 options
. Often the worst offenders end up with data being backed up directly to backup appliances. How did we get here? I’d like to explore some of the architectural challenges facing data protection today and why dedupe appliances often fail to live up to their promise.
Disk-based dedupe appliances were not inherently bad on their own. When they first hit the market they were a great drop-in replacement for Tape. They reduced the need to manually swap tapes, and for backup workflows that sent highly duplicate data over they could optimize and compact this data. They added a significant amount of computing to these appliances so they could highly optimize data ingest speed as well as provide data reduction that previously backup software tended to not handle, or not handle well. If you wanted to stuff a lot of data into a box they were pretty useful.
This baby can hold 800TB! Restore Speed? What’s that?
The challenge of Dedupe Appliances is at the cost of being “good” at holding lots of data, they tend to be fairly bad at recovering said data. When you stuffed hundreds of virtual machines into them, often people think “how am I going to get them out of this data center clown car?”
You can fit 2000 VMs in this car!
Backup vendors have long been asked to “perform magic” and deliver faster and faster restores, despite the “physics” of moving large amounts of data taking too much time. One way to “Cheat” that has become popular is to expose an NFS share as a datastore and allow a virtual machine to be “booted” from the backup repository. Veeam Instant Recovery was an early mover in this space, but other backup vendors and DRaaS solutions have adopted similar capabilities. This works great as it avoids the traditional bottlenecks of the source and target disk speeds and network and goes straight to a running VM… RIGHT? I’ll just power on the virtual machine and then storage vMotion it over later!
Bring on the Clowns
One of the challenges of trying to run a production virtual machine is it expects the same IO performance as your primary disk. 8 years ago when primary storage was 15K RPM drives, and backup appliances used 7.2K drives that were 1/3 as fast this might have been problematic, but doable especially for a single virtual machine. Today, application owners EXPECT flash-based primary storage that delivers 100K IOPS per host at low latency. Using 7.2K drives that deliver 100 IOPS each, at 30ms+ of latency is well… A clown show. Trying to run a database virtual machine off of this storage is a bit like trying to jump-start a 737 airplane using a motorcycle engine.
How do we solve this problem?
There are quite a few approaches I’ve seen to try dig out of this hole once people realize this is not going to work:
Identify that the vendors never promised it would work or often had limited promises (Some vendors often will support a low single digit number of virtual machines).
Move to a 2 stage backup system, where backups land on a all flash DAS system initially and then copy out to the appliance for long term retention. (Similar to Disk to Disk to Tape workflows of old). This allows you to keep using the appliance, but just use it for what it best used for. Tiering this data out to an object storage bucket is increasing the “right choice” vs trying to have an all in one appliance.
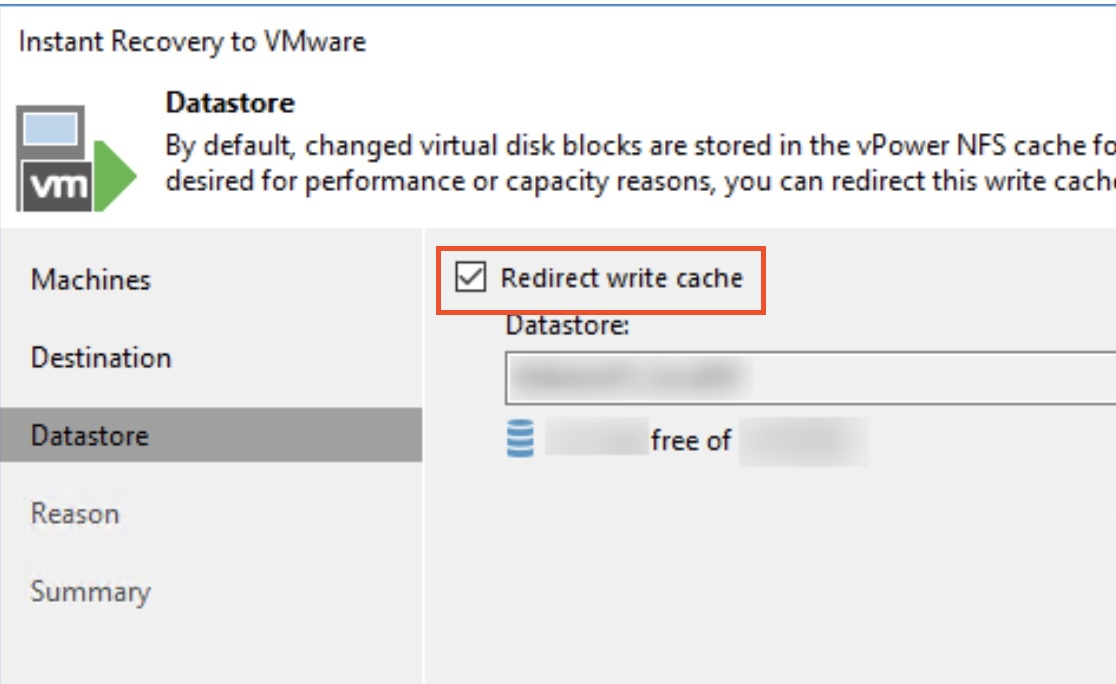
Use caching to solve or partially mitigate this (Veeam can redirect writes, but even with this option a read heavy database on a slow dedupe target will suffer).
Look at All Flash dedupe appliances or ones with large flash caches (Personally I’m not sold on this idea vs. just depoying a set of DL380/Apollo servers full of flash as the primary landing zone).
Redirect to the datastore you will recover on
Disaster Recovery to the rescue.
I’ve had chats with a few customers lately who’ve recognized that for large-scale recovery of anything important, the backup repository speed is unsalvagable. Instead they “punt” and move to split out those critical recovery workflows to be powered from Replica’s that sit on a primary storage solution somewhere else. They may choose a second data center, but increasingly a DRaaS option is often making more sense, as maintaining a data center that sits idle often is not worth the effort. The other benefit of shifting to DRaaS is it often can be tied to immutable retention and provide additional ransomware recovery capabilities.
This guy always has another backup copy job running
The greatest storage and systems administrator of all time was Montgomery “Scotty” Scott. No matter how far outside of design the ship was pushed he generally found away after saying “the ship can’t take anymore” to find the capacity to prevent disaster. His key secret?
Expectation setting (He always looked good when he under promised and over delivered).
Hiding reserve capacity (A key tallent in many storage management practices).
A magic ability to get limitless budget for repairs, replacement parts and ships.
The reality in storage management is we can not all be Scotty (nor should we need to be). Sometimes we end up in scenarios that the system was not designed for. Thankfully there are sometimes capabilities of storage systems that vendors can expose that allow us to opportunistically exceed design expectations and “win” in Kobayashi Maru “no-win” scenarios. When data has gone missing or is expected to be gone for good, what is involved in your plan?
When planning disaster recovery or business continuity should you include “Might be there” safety nets? When drafting target Recovery Point Objectives (RPO) or Recovery Time Objectives (RTO) should or can you count on these vs. properly investing in a good backup/disaster recovery solution?
Restore Accidentally Deleted LUN
A lot of data loss scenarios are murkier to plan for than you realize Accidently deleting a LUN is a shockingly common occurrence. Poorly updated LUN number abstraction maps, and separation of duties (3 people involved in identifying a volume to delete on a SQL cluster) can all lead to this.
Some storage arrays have magic un-delete buttons. This can range from a trashcan to an obscure command that requires support to invoke. This capability is generally contingent on free space being available to retain the data that was deleted. I’m always nervous about including this in an RPO/RTO promise. The problem is in an out of space condition one of two things happen when counting no this capability:
1. The array will go read-only and crash every virtual machine (well abruptly pause if VAAI is working)
2. The snapshots will auto-delete
“But John I don’t have a high enough change rate, and I run my array at 20% usage!”
This may be true, but ransomware has a nasty habit of:
1. Re-writing all of your data.
2. Encrypting the data so that 4x dedupe and compression turn to a negative dedupe rate. Either of these activities can trigger an out-of-space condition.
You also need to be concerned with ransomware like IO activities coming from your users/application owners:
DBA decides to turn on encryption on a database and doesn’t tell anyone.
Large batch process re-writes the data
Large data ingestion events
“But why would this problem happen at the same time I’m deleting a LUN?”
One of these things often causes the other. An out-of-space condition will often make all volumes on an array go read-only. This generally forces a storage admin to delete LUNs quickly. This outage often can happen at weird hours without proper caffeine, visibility, or communication.
Capacity Reservation Mitigation
Preventing out of space conditions (to prevent this scenario) can be done by “always provisioning thick” and reserving 110% capacity for snapshots, but practically the costs associated with doing this with storage that doesn’t tier into cheap S3 isn’t a feasible solution for all but the most deep-pocketed of datacenters. It may be tempting to “throw primary storage” at this problem, but that budget is often better invested in other mitigations.
Unplanned Data Loss
Other scenarios where “maybe I can recover your data” tools come into play are failures that exceed the design of the storage platform.
Force Rebuild
An example that would cause this is the rebuild of your 92 SATA disk RAID 5 hits a Latent Sector Error (LSE) causing an Unrecoverable read error. A single read failure in this situation causes the raid rebuild to stall. In theory, your data is lost. Depending on your platform and the tooling of your storage partner though, you may be able to accept a small amount of data loss and force the rebuild to go forward anyway.
Luck based rebuilds on multi-drive failure
Some platforms limit the rebuild domain for an LSE impact by using per volume RAID/rebuilds (vSAN does this) to reduce the impact of a drive failure that exceeds tolerance. Depending on how the error works you could be accepting an unspecified corruption of a few files or you could be hoping for “luck” in where the error is to not lose data. The only thing I like to count on in design for these is the speed of recovery. Rather than need to invoke a disaster recovery plan on 3 of 100 drives failing simultaneously, knowing I only need to rehydrate 3% (or potentially much much less) of the data from backup helps with planning cache/simultaneous restore plans.
Overriding split-brain protection
Specific to vSAN if you had a thermal meltdown in the data center on your HCI cluster and lost quorum and 1 copy of the data on a RAID 1 mirror from the cascading cooling failures you would have data unavailability. You can call support and they can upload a recovery tool to attempt to defy the angry storage gods and clone a full copy.
All of these scenarios involve a few things:
1. Operational failures.
2. Design failures of some kind.
3. Require the equivalent of a D20 dice roll to get your data back.
If you needed one of these “might be there” recovery options to hit an RPO/RTO/SLA it generally can be solved by better design.
How to better prevent accidental deletions
VASA/vVols
If you live in a data center with highly SILO’d ITIL operations, miscommunications are a risk in all operational changes that involve storage volumes/LUNs. There are a few ways though to improve communications and reduce errors between the storage and virtualization teams.
vSphere Storage APIs for Storage Awareness (VASA) allows VMware administrators better visibility into the storage layer. This allows VMware administrators to have a vision into what the internal volume numbers are for a given virtual machine or datastore.
Virtual Volumes simplifies communication even further by offloading the deletion task entirely to the VMware administrator. Deleting a virtual machine automatically deletes the associated volumes with it, removing any miscommunication between the VMware and storage team.
Operational Methods To Prevent Accidental LUN deletion
The best operational advice for storage arrays I have is to train your staff to disconnect LUNs and then wait 48-72 hours before deleting LUNs. There shouldn’t be an urgent need to delete a LUN.
“But John we urgently need that space back!”
Pretty much all modern storage arrays support TRIMUNMAP/DEALLOCATE as a way to allow the operating system/hypervisor to perform deletions from a higher layer and push through those deleted blocks. Rather than blindly deleting an entire volume, making sure deletions of VMDKs are pushed through from VMFS is a much safer/easier alternative. Auto shrinking VMDKs also allow for deletions from guest OSs to be pushed through end to end. The closer you can delete data to the application the less chance you risk miscommunication.
Lastly, using vSAN or vVols simplifies this further. If you delete a VMDK the space is freed up, and vSAN supports thin volumes shrinking by UNMAP/TRIM from the guest OS in the virtual machine. vSAN and vVols pierce through layers of abstraction to make storage capacity management just a simpler way to handle things.
Final Thoughts?
These various “tricks” are great when they work. I still don’t think they play a primary role in planning your recovery speed, or the point of recovery for recovering from failure. The smartest thing Scotty ever did was keep his “might work” tools in his back pocket and promise only what the ship was designed for.
This blog came about from a conversation with some of the other Veeam Vanguards.
A while back I spoke to some customers who were trying to test VDI. They wanted to spend several months testing out multiple storage systems for a VDI system for 500 users. This was rather confusing to me, as the labor time spent validating the storage was likely going to cost more than just throwing a reasonably beefy all-flash cluster at the problem, and properly configuring Horizon for their use case. The first use case they were concerned about, as they were testing copying an ISO from one desktop to another. It was slower than a test they ran in another VM. Upon further investigation, it was determined:
They were not testing an actual copy in both instances (One was being offloaded using Microsoft ODX).
Their test (if it was working) was a test of a low queue depth large block write operation. This wasn’t consistent with a review of vSCSI traces of their existing VDI use case.
It was still fairly fast when comparing against someone’s laptop.
Interviewing the use case (Doctors in a hospital) and having a consult with my wife (MD) it was determined that doctors do not copy large ISO files as part of their daily acivities
Normally the best testing of VDI is:
Spin up a test pool and redirect some users on the pool (taking care to select users who will be using the same applications and workflows as the users that will be scaled later).
Use a VDI benchmarking application taking great pains to properly configure it. I will note on LoginVSI published benchmarks you sometimes see some hilariously non-realistic desktop testing done to publish “hero numbers”.
Pull a vSCSI trace and use a automated scaled stesting system to “replay” an amplified synthentic copy of the storage requirements (note this doesn’t test CPU in the same way).
Upon further discussion they decided to just put some users on the cluster, perform a proper pilot test, and scale at user densities they were able to achieve on the pilot going forward. Here is a review of some of the mitigations and discussions we had that helped cool off the storage team’s fears.
Why is VDI percieved as demanding on storage?
Virtual Desktops in the past were known to be a “Scarry” storage heavy workload that put fear into storage admins and brought disk arrays to dust. Why was this?
Boot Storms – Recompose actions or under-provisioned pools needing to catch up with demand would lead to OS boot events. While the steady-state IOPS per desktop might be in the single or two digits, this could result in a spike of 800 IOPS or more per desktop.
Login Storms – Roaming profiles with hundreds or thousands of users who all log in at the same time resulted in huge amounts of data being copied into desktops.
Antivirus Scan Storms – Copy pasting the security posture of your existing desktops, often leads to the security team trying to scan every desktop at noon at the same time.
The reality is these problems have been largely solved (for years), but have sometimes been perpetuated as still issues by storage vendors trying to sell some feature or solution. *Disclaimer, I work for a storage product and while I’d love you to buy vSAN and think it is frankly awesome for VDI, I’m not going to pretend that the above problems can’t be largely mitigated in other ways*.
Boot Storm Mitigations
Use Instant Clones – Instant Clones are “born running”. They use VMFork technology to create writable snapshots of the memory of a running virutal machine. This has the advantage of insanely fast (seconds) desktop creation times.
Pre-stage desktops/rolling recompose – At some scale you can always just schedule recompose operations. A popular trick I used back in the stone ages of lined clones was to create a new pool and set it to auto-scale. I would disable net new connections to the old pool and set the users to only see the new pool. This allowed for a slower transition to the new pool. Combined with throttling new desktop creations to a manageable speed this new pool could slowly grow to the needed capacity. This required a few slack resources but the vSphere scheduler and memory compaction technoligies was generally good for it if you were not running absurd vCPU rations, to begin with. Note, other methods largely solve this from a resourcing method but this method can still be used as a means of slowing testing a new image and allow for rapid “roll back” if the new image has issues (re-enable the old pool and direct new connections back to it).
Cache the blocks used for OS boot – This has been discussed before, but OS boot only needs to call up a few hundred MB of blocks into RAM. Various VDI solutions to provide a DRAM cache to hold these blocks have existed for years (Horizon Content-Based Read Cache, or CBRC). This allows multi-GB read caches to be deployed for the base OS disks to accelerate them. Citrix also with PVS has similar capabilities. Beyond this modern storage arrays with dedupe and multi-hundred GB DRAM caches will make short work of these bits. Remember even for “full clones” any solution with dedupe (or dedupe cache like CBRC) can handle the fact that is it 300MB of hot blocks X 2000 Desktops. vSAN even goes so far as to put DRAM cache local to the hosts where VMs are running to reduce even storage network traffic hits.
Login Storm Mitigations
Profile Virtualization – Technology to cache, and optimize profile load through various mechanisms have been around for a while. While I was cutting my teeth on Persona years ago (which worked, it just required you to know which folders to exclude from the stubbing system) VMware Dynamic Environment Manager is a fantastic solution today. FXLogix and other solutions also exist that can even deal with some of the more annoying elements of profile virtualization *GLARE INTENSIFIES AT OUTLOOK OST FILES THAT DROVE ME CRAZY *. It’s true we used to have to do weird/stupid things with application customization to make profile virtualization work (Make sure Exchange was colocated 1ms from the VDI pool) but those days are long gone.
Antivirus Storm Mitigations
I’ll leave others to speak more in the comments to this one, but a blend of on-access scanning policies and agentless and network-based introspection has largely calmed the challenge of virus scans taking out a cluster. Security is about many layers of an onion providing security here.
Other Minor VDI Resource Issues to think about
Windows Search – This and other services we used to disable to better optimize desktops. I’ll call out that disabling this also breaks outlook email search and even if this leads to 3% increase in density I would argue you don’t need to go to these extremes to optimize desktops. While there are certain things you should optimize, breaking user experience to get an extra 10 users in a cluster likely isn’t worth it anymore. Hardware is cheaper at this point than the emotional cost of annoying users.
Hardware refreshes need to be at way more than 1:1 –I advised a bank recently that was replacing an ancient 5.5 environment with windows XP desktops. They were expecting that by buying hosts with 5x the resources they would get 5x the host density. They were disappointed to learn that:
The 3 anti-virus solutions they had installed were at war with each other for the 1 vCPU’s they were allocating to each desktops and over subscribing 15:1
1GB of RAM wasn’t enough to make users happy
Their base images were now 6x larger
The reality is we used to make some awful compromises on VDI usability and user experience to make the numbers “work”. Make sure when sizing solutions to understand that with lowered resource cost comes options to do more than save capital costs.
But John? What if I Can’t do X,Y,Z?
Just throw a little more all-flash storage at the problem. We used to get excited about getting the cost of storage down to $100 per user for VDI. Now with all-flash, instant clones and dedupe the storage costs have kind of become a rounding error on the total VDI solution. There used to be an entire field of “VDI storage-specific vendors”, and you’ll find that most of them have completely disappeared. This is because the problem of VDI and storage has largely gone away.
Having been around the industry I’ve noticed there are a lot of changes but a few guarantees when it comes to benchmarking shared storage and HCI clusters:
Benchmarking is generally poorly represenatatitive of what the production workload will look like.
Benchmarking is about trade offs. There are “easy” ways to do them, but often these are so far from accurate for what production will look like they might as well be skipped.
Real benchmarking is hard. There are shortcuts to easier benchmarking. Some are good, some are bad. It’s critical either way you understand what trade offs you make when you chose one.
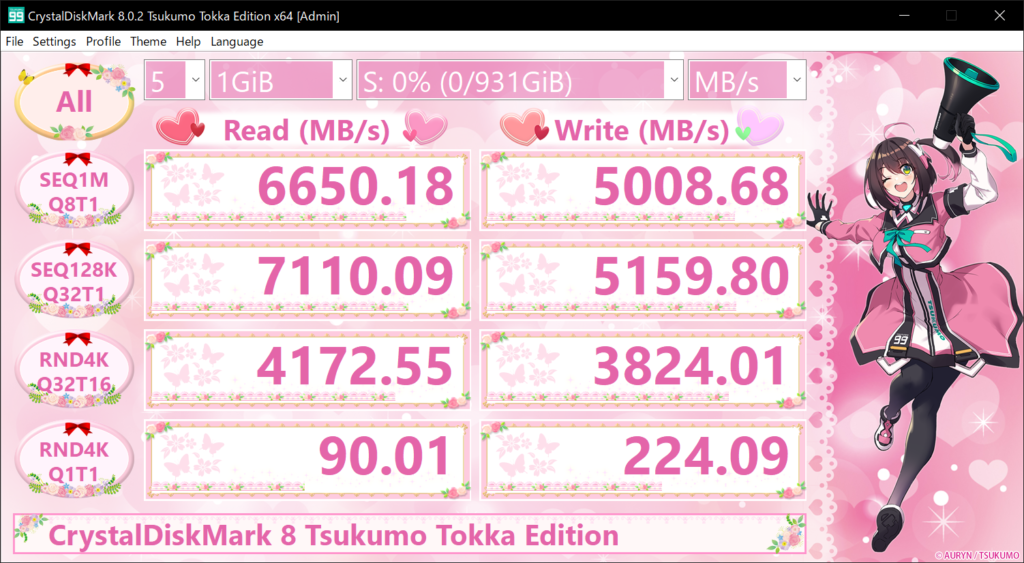
There are good easy buttons for testing a cluster (HCI Bench is a personal favorite) and there are bad easy buttons (Crystal Disk, ATTO Disk, IO meter, and other synthetic workload desktop-focused testing tools). Today we are going to talk about why single workload tests are normally poorly done.
It’s often poorly executed – The single workload test
A lot of people can spin up a single virtual machine, fire up a synthetic disk testing application like CrystalDisk or IOmeter and push “Test run”. While this does generate IO, it doesn’t necessarily generate a workload against an HCI cluster that looks anything like what a customer would run. Breaking down some quick fundamentals.
In your typical VMware cluster, you will find multiple virtual machines with different numbers of drives processing different block sizes, read-write mixtures, different overlaps when they send data (Some bursty, some constant).
Even clusters with homogonous dense workloads don’t look like this single VMDK test. Even monster scale-out in-memory databases like SAP HANA and Casandra and container platforms recommend more than 1 virtual machine. Amongst these applications, you still will always see more than 1 virtual hard drive (VMDK) processing disk IO, possibly with multiple vHBAs attached.
Other common mistakes that go along with using these tools:
The default Crystal Disk only uses a relatively small working set size (below 5GB). In any tiered/cached system, there is a strong chance you end up testing IO that largely is served from DRAM caches (either inside the SSDs or within caching of the system). A 24/7 production environment with large data flows will result in wildly different outcomes.
IO Meter can be configured for multiple workers, but doing so at scale with a diverse set of workloads is going to be problematic vs. using something that has better synthetic engines with more options and easier control and reporting like HCI Bench. It’s worth noting that IOmeter has seen 1 release since 2008 when Intel made it abandonware. VDBench and FIO that are used by HCIBench have seen a lot more development attention.
Fixed QD or block sizes. Crystal Disk tests 4 different blends of block size and queue depth but:
There’s a strong corelation between people fretting about large block throughput, and people who are running workloads that don’t actually send large blocks.
The tests are run sequentially, and not in parallel. Again, real storage systems handle what is thrown at them and can’t ask applications to nicely wait 30 seconds for their turn to run a homogeneous workload.
These workloads tend to generate high entropy data (So no dedupe/compression). It could be argued that setting the workload to include to low of entry is cheating but using real data sets (or tuning synthetic to mirror entropy of the real data) is going to give you a more accurate idea of what production will look like.
Not reporting latency is a bit like reporting horse power and top speed of a car but ignoring torque when people want to tow a boat…
There also is a fatal flaw in CrystlalDisks presentation of data. It’s a simple average summery for each benchmark that fails to show a time series of data. Without understanding what a system looks like at the beginning of a test (When cache may be less warm, but write buffers less full) vs. the end of the test (when cache hits may increase, or buffers may be exhausted) its very hard to understand what steady state under load performance may look like. This is magnified further in that Crystal Disk and the like are short tests. For systems that will run under load for hours/days you want tools that can sustain testing to better emulate your production duty cycle for IO (Not that it would make a good synthetic workload generator if you could run it for longer). Often things like tail latency, jitter or 99% latency can have disastrous impacts on systems that users have to interact with.
Who wouldn’t test their 10 Million Dollar ERP solution with this “serious” testing tool!
A good storage system has to handle a wide variety of workloads simultaneously. The single workload/disk test is a bit like testing the effectiveness of an air traffic controller at an airfield that sees 1 airplane a day. You might see the different variations in his communication quality to that one airplane but any serious test is going to stress tracking different planes on different trajectories.
Next up, Bad VDI testing – No Copying an ISO is in not benchmarking VDI…